从统计推断到因果推断:传播学定量研究中的内生性问题
发布时间:2021-06-23 10:49:49 点击数:
一、引言
随机实验 ( 包括各种准实验) 通常被认为是识别变量之间因果关系的最值得信赖的方法。然而, 在新闻传播学领域的研究中, 因受资金、规章和伦理等条件的制约, 科研人员经常不得不使用非实验数据 ( nonexperimental data) 来从事科研活动①,通过这些观测数据 ( observational data) 或者回顾数据 ( retrospective data) 来进行因果推断则是一项颇具挑战性的工作②。其中一个主要的原因就是观测数据基本上都带有与生俱来的内生性问题 ( endogeneity) , 也就是解释变量和误差项的相关性问题。内生性问题会造成回归方程中参数估计的不一致性, 是研究人员进行因果关系识别和理论构建的巨大障碍。因此, 在潜在结果框架下对这些问题的处理, 也成了社会科学现代定量研究方法教学和应用的核心问题之一。
而从当前的教学和科研情况来看, 传播学研究方法类流行教材中定量部分的相关内容将重点更多地放在了如何来收集观测数据, 以及如何利用此类数据进行回归分析和统计学意义上的显著性推断上。在主流的新闻传播学期刊上, 典型的应用定量方法进行因果关系推断的论文也基本上都遵循了 “观测数据———回归分析”的模式。而这种研究模式对观测数据的策略性识别以及对内生性问题的处理方面仍有提升的空间。在无法剔除内生性影响的情况下, 直接通过观测数据来进行统计推断,并根据统计学上的显著性水平来进行因果关系推断和理论构建的难度比较大。
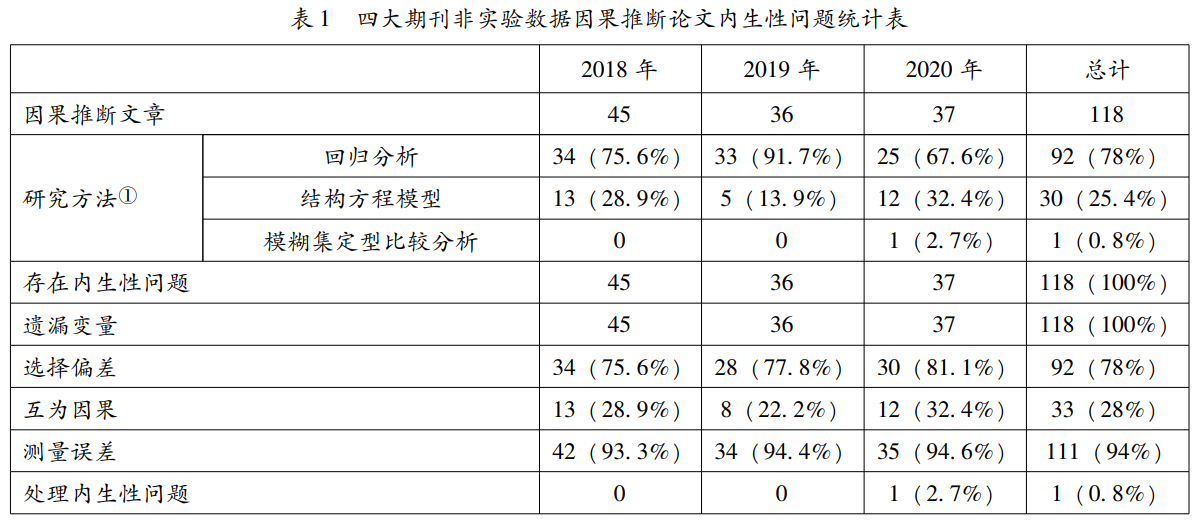
从 2018 年至 2020 年 11 月, 新闻传播学领域的传统四大期刊包括 《新闻与传播研究》、《国际新闻界》、《新闻大学》和 《现代传播》共发表了基于非实验数据的定量分析方法类论文 210 篇, 其中涉及到因果关系推断的论文共 118 篇, 占比约为56% ②。此 118 篇论文均存在内生性问题③, 其中存在遗漏变量偏差的论文共 118 篇( 占比 100% ) 、选择偏差共 92 篇 ( 占比 78% ) 、互为因果共 33 篇 ( 占比 28% ) 、测量误差共 111 篇 ( 占比 94% ) , 同一篇论文内常会出现多种内生性问题, 而其中仅有一篇文献讨论了数据的内生性问题并尝试使用工具变量法 ( instrumental variableapproach) 来尽量减小各类偏差对因果关系的威胁④。可见, 内生性问题一直都普遍地存在于传播学领域的研究当中, 并未得到有效的解决, 这也一定程度上说明了本篇文章所要探讨的问题的重要性与必要性。
事实上, 在 “观测数据———回归分析”模式下发现的解释变量和因变量 ( 被解释变量) 之间统计学意义上的显著性关系, 往往只是相关关系, 而这些相关关系通常可以通过非控制性质的研究直接得到①。要对因果关系假说进行实证检验, 从相关关系进步到因果关系, 在非实验条件下, 还需要研究人员思考相应的研究设计, 并对数据进行更多的识别和进一步处理, 以剔除内生性问题的影响。当然, 除了对数据的识别以外, 构建变量间的理论联系也极为重要, 不仅能帮助我们有效地建立起对应的逻辑关系, 也有助于我们重新思考实证分析的结果和研究的过程。这一点,也常常被众多的定量研究论文所忽略。接下来, 本文首先讨论目前新闻传播学研究方法类流行教材中关于定量部分的内容, 以及在传播学研究中使用非实验数据进行因果推断的主要模式。
二、定量研究方法在新闻传播学中的应用问题
“研究方法服务于研究问题与研究目的”是科研人员的共识, 如何使用定量方法要取决于研究的具体目的, 若目的是观察变量之间的相关关系, 那么尽可能地增加样本对其而言更为重要; 若目的在于使用量化数据来进行因果关系推断, 那么研究的重点和难点并不在定量方法本身, 而在于如何来设计此项研究以合理地运用数据, 解决内生性造成的参数估计不一致性以及这种影响对理论结论的干扰。而新闻传播学的研究往往更多的是基于观测数据来探讨变量间的因果关系②, 因此, 为了排除数据的内生性干扰, 研究设计 ( research design) 是新闻传播学定量研究中极其重要的一环。
如在媒体建构与民众的社会公平感的变量关系中③, 研究者无法通过 “观测数据——统计推断”的定量分析方法验证核心论述——“民众的社会公平感是社会媒体建构和社会建构的结果”, 因为这样的论述和基于的分析模式几乎面临着来自内生性问题的各个方面的挑战。比如, 社会为什么会形成目前的媒体建构, 或者说目前的媒体建构是如何形成的? 几乎没有人会认为一种社会媒体建构的出现是一个随机过程, 那么一个潜在的合理解释便是这种媒体建构源自于民众 ( 所需要) 的社会公平感, 即社会公平的需要促成了当前的媒体建构形式, 而非后者决定了前者。所以,在逻辑上 “民众的社会公平感是社会媒体建构和社会建构的结果”这个核心论述就存在着互为因果的最为典型的内生性问题———原本假设是纯外生变量的媒体建构实际上却是一个被因变量决定着的内生变量。更近一步的, 社会为什么会同时形成目前的媒体建构和民众的社会公平感? 一个潜在的合理解释是这种结果是受到了社会政治制度的影响。于是政治制度便作为一种混淆变量 ( confounding variable) 同时影响了 X 和 Y。其他的内生性问题如选择偏差和测量误差等同样可能威胁到以上所说的核心论述。所以, 在回归分析中所发现的 X 和 Y 之间的关系很可能并不是因果关系。更严格地讲, 在这一类基于 “观测数据———统计推断”的传播学研究中所得到的参数估计, 与总体实际的参数经常是不一致的。因此, 这种定量研究设计思路对新闻传播学理论构建的帮助作用还有可商榷之处。
由上例可知, 为了探究民众的社会公平感是否会受到社会媒体建构和社会建构的影响, 真正的重点和难点并不在于如何收集观测数据以及进行某种形式的回归分析, 而在于如何设计一个有针对性的研究方案, 使得具有内生性的社会媒体建构和社会建构这些解释变量至少可以部分地外生化。在无法采用实验或准实验方法的情况下, 无法真正随机分配解释变量, 所以能否成功地采用一种基于观测数据的研究设计以尽量避免内生性问题是研究成败的关键。
目前在新闻传播学流行的研究方法教材中和主流期刊上, 在如何处理观测数据带来的内生性问题等方面, 仍然有较大的改进余地。目前方法类教材的量化研究方法重点在于如何得到观测数据, 以及如何进行推断统计上, 而对研究设计以及数据识别策略等处理内生性问题的各类方法介绍得还不够全面。类似的, 近年来在新闻传播学领域, 大多数的定量论文都采取了 “观测数据———回归分析”的模式来进行因果关系推断。同样也缺少了数据识别策略部分。绝大多数论文都未提及、未解决调查数据所存在的内生性问题。下面以一个具体的例子来进一步说明究竟什么是内生性问题以及它会对传播学的定量研究造成什么样的影响。
在 “哪些因素影响了新闻从业者的职业承诺”这一问题上, 研究者认为是从业体验等因素对新闻从业者的职业承诺水平产生了显著影响①。其通过问卷调查得到了yi = α + β xi + γ zi + εi ( 1) 在 ( 1) 式中, yi 为因变量, 表示新闻从业者的职业承诺。显然, 由于 yi 是要被模型决定的, 所以 yi 是内生的 ( endogenous) 。xi 是研究所感兴趣的解释变量, 新闻工作者的从业体验。在进行参数估计时, xi 必须是外生的 ( exogenous) , 即由模型以外的其他因素所决定的。zi 是一些控制变量包括年龄、性别、教育水平等; εi 为模型相关的残差项。
当高斯 - 马尔科夫定理 ( gauss-markov theorem) 成立时, 利用 ( 1) 式和调查数据就能得到 β 的最佳线性无偏估计 ( best linear unbiased estimator, blue) , β^ 。值得注意的是, 如果 xi 确实是一个外生变量, 那么利用 OLS 得到的 β^ 就是一致的。也就是说, 这种情况下如果调查取得的样本量比较大, 估计出的参数会趋近于总体的真实参数。但是, 如果 xi 是与残差项 εi 相关的, 那么此时 xi 就不再是一个外生变量, 而是具有了内生性的变量。这种情况下直接通过 OLS 回归分析得到的参数估计就是不一致的①。如果参数的样本估计值与总体的真实值之间不具有一致性, 那么该回归分析对变量间因果关系识别和进行理论构建的帮助是比较有限的。
回到新闻从业者的职业承诺的例子。解释变量 xi , 新闻工作者的从业体验, 很显然不会是一个随机取值的变量②。比如它很可能跟个体的收入和职务有关; 也很可能与工作单位的类型, 比如央视、人民日报还是县级融媒体中心等因素有关。在回归模型 ( 1) 中, 这些与解释变量相关的变量被归入残差项后, 得到的新闻工作者的从业体验对其职业承诺的参数估计就极可能是一个非一致的估计, 所谓的显著性影响很可能只是表面上的相关性。
总之, 内生性问题在新闻传播学研究中广泛存在。在使用非实验数据比如社会调查数据的情况下, 内生性问题是进行因果关系推断的巨大障碍。因为此时无论采用什么形式的回归分析技术, 所得到的回归显著性均不能推断出变量间的因果关系,一般只能识别解释变量和被解释变量之间的相关关系。接下来, 在分析了相关关系和因果关系之间的联系与区别后, 本文将借助实例来重点讨论形成新闻传播学领域中观测数据内生性的主要原因。
三、新闻传播学研究中的相关关系和因果关系
在定量研究和统计学中, 相关性或者相关关系 ( correlation) 指的是两个随机变量之间的线性相关关系③。相对而言, 因果关系的定义要比相关关系复杂一些。在现代社会科学中, 被广泛接受的因果关系的概念是建立在潜在结果框架 ( framework of potential outcomes) ①, 或者也被称为 Rubin 因果模型 ( rubin causal model, RCM) 基础上的②。RCM 因果模型中有三个基本构成部分: 潜在结果 ( potential outcomes) 、分配机制 ( assignment mechanism) 和个体稳定性假设 ( the stable unit treatment valueassumption, sutva) 。在 RCM 模型下, 因果关系效应 ( causal effect, 或者干预 /处置效应 treatment effect) 被识别为对于任何一个个体, 有无干预或者处置 ( treatment)在两个潜在结果之间的差别。当然, 实际的定量研究所关注的焦点是对于两组个体,有无干预在两个潜在结果之间的平均因果效应 ( average treatment effect, ate) 。
在实际的科研活动中, 科研人员并非总是使用线性回归模型 ( 或单纯的线性相关关系) 来辅助进行因果关系推断。但是: 第一、使用其他模型比如 Logistic 或者Probit 等回归模型所发现的统计学意义上的显著性, 在多数情况下使用 OLS 模型同样可以得到。第二、从 OLS 模型到因果关系推断之间面临的主要困难 ( 内生性问题) 在其他模型中同样存在。为了简便而不失一般性地说明问题, 本文接下来对所有用于说明性质的回归方程都统一使用 OLS 模型。
定量研究中得到的相关关系并不意味着因果关系 ( correlation does not imply causation) ③。但是在新闻传播学的研究中, 仍然存在通过使用相关性的研究设计总结出因果性结论的研究。在这些研究中只存在验证解释变量和因变量之间相关性的设计, 而没有任何能够说明因果关系的设计。例如, 假设研究问题是 “政治相关新闻的接触, 是否会对政治参与行为产生影响”④, 当使用以下标准的 OLS 模型来进行推断时:yi = α + β xi + εi 内生的因变量 yi 为政治参与行为, xi 表示政治相关新闻的接触, εi 仍是模型的残差项。回归系数 β^ 可以用向量形式表示如下:β^ = ( X'X) -1X'Y 即使回归系数 β^ 是非常显著的不等于 0, 依然无法得到政治相关新闻的接触会对政治参与行为产生影响的因果性结论。因为依据 β^ ≠ 0 得出因果关系的前提是 ( 2)本身必须包括因果效应的解释⑤, 而这一点显然不满足。理论上当然有理由认为政治相关新闻的接触可能会对政治参与行为产生影响。但是, 同样也有理由认为政治参与行为本身就会影响人们对政治新闻的接触。当把 ( 2) 中 xi 和 yi 的位置互换后再重新进行 OLS 回归分析, 会得到完全一样的结论。这种 OLS 回归方程本身并不能得出与因果关系有关的信息。目前新闻传播学领域的一些研究都是通过增减模型的解释变量并观察回归方程给出的 R2 的变化来验证解释变量对因变量的影响。这种设计通常只能检验解释变量和因变量之间的相关性, R2 的变化本身并不能说明变量之间有或没有某种因果联系。关键的问题是, 即便假定相关新闻的接触对每一个个体的影响是相同的, 不会存在个体上的差异, 仍难相信每个个体对政治相关新闻的接触是随机的。换句话说, xi 并不是一个外生变量, 它可能与个体的政治态度相关, 与个体以往的政治参与行为等等很多形成内生性的因素有关。当把这些因素归入随机误差后, 回归系数 β^ 所包含的信息远远多于 “政治相关新闻的接触对政治参与行为产生影响”。
而在潜在结果框架下, 一个 OLS 模型可以得到一个因果效应的解释: 假设一个因果关系问题 “社交媒体中的社交使用对青年的个人信息权意识有促进作用”①。为简单并说明问题起见, 这里假定社交 APP 有两种使用方式, 一种是社交使用, 另一种是非社交使用②。进一步的定义干预变量是 APP 的社交使用情况并用 T 表示干预状态。对于任意的个体 i 存在两种干预状态, 其中 Ti = 1 表示个体 i 社交使用该 APP,Ti= 0 表示个体 i 非社交使用该 APP。用 Y1i 表示个体 i 在状态 Ti = 1 下的个人信息权意识, Y0i 表示个体 i 在状态 Ti = 0 下的个人信息权意识。那么观测结果可以用潜在结果的形式表示成:Yi= α + τATE Ti + εi 其中: α = E[Y0], τATE = E[Y1] - E[Y0],误差项εi = ( 1 - Ti) × ( Y0i - E [Y0i]) + Ti × ( Y1i - E [Y1i]) τATE是平均干预效果, 或者平均因果效应。
( 4) 式虽然在表面形式上与 OLS 相同, 但其表示的是处置变量与潜在结构间的因果关系, 并非 OLS 模型。控制组和实验组的结果均值, 也就是青年的个人信息权意识的平均值在社交使用和非社交使用 APP 时分别为:
现在假 定 APP 的 社 交 使 用 与 青 年 个 人 信 息 权 意 识 之 间 的 条 件 期 望 函 数( conditional expectation function, cef) 满足线性关系。如果想利用 ( 2) 式中 OLS 的回归系数来做因果效应解释, 那么回归系数 β^ 就应该等于 ( 5) - ( 6) 。也就是:
β^ = E[Yi | Ti = 1] - E[Yi | Ti = 0]
= τATE + { E[Y0i | Ti = 1] - E[Y0i | Ti = 0]}
+ ( 1 - p) { E[Y1i - Y0i | Ti] 1 = - E[Y1i - Y0i | Ti = 0]}
其中 p 是任意一个青年个体在控制组中的概率, 也可以理解为控制组成员所占的比例。显然, 要使用 OLS 的回归系数 β^ 来解释潜在结果模型中的因果关系必须满足两个条件①:
条件一: E[Y0i | Ti = 1] - E[Y0i | Ti = 0] = 0 。即每个个体在 APP 的社交使用和非社交使用中不能存在选择偏差。
条件二: [Y1i - Y0i | Ti = 1] - E[Y1i - Y0i | Ti = 0] = 0 。即 APP 的社交使用对个人信息权意识的影响在每个个体上不会出现差别。
回到案例中, 在使用观测数据的条件下, 条件一很难得到满足: 是什么原因导致了有的年轻人使用 APP 的社交功能, 而其他人使用了 APP 的非社交功能? 很难相信每一个年轻人使用什么样的社交媒体或者使用社交媒体的哪一部分功能完全是随机的。那么导致年轻人使用 APP 的某些功能的原因会不会本身就是影响他们个人信息权意识的原因 ( 一个混淆变量) ?
在潜在结果框架下, 同时满足以上两个条件的一个充分条件是年轻人的个人信息权意识的潜在结果独立于社交媒体的使用, 也就是满足条件独立假设 ( conditional
, Y0i) ⊥ Ti 并且数据满足 CIA 条件时, 就可以用 OLS 来进行因果关系识别。但是, 由以上案例可见, 在 RCM 模型中, 内生性问题的主要表现形式就是样本选择偏差。在新闻传播学的研究中, 各种观测数据的获得, 比如各种调查很难满足 CIA 条件, 这种情况下的形成内生性问题的原因就更加严重和复杂, 也就无法直接通过 OLS 或者其他回归模型来帮助进行因果关系识别。
四、新闻传播学定量研究中的内生性问题
实验方法无疑是进行因果推断最为有效的方法。但是在社会科学, 尤其是在新闻传播学的研究中, 更多的情况下, 研究人员只能依据观测数据来发现因果关系。在非实验数据条件下, 解释变量与残差项之间出现相关性的内生性问题很容易发生,从而导致参数估计的不一致性, 无法有效地帮助识别解释变量和因变量之间的因果联系。在这一节, 本文仍然通过新闻传播学中的实例来说明在使用观测数据进行因果关系推断时经常会遇到的四种内生性问题。值得注意的是, 当使用非实验数据时,多种形式的内生性问题经常会同时出现在一项研究中①。
需要说明的是, 除了部分使用国内统计年鉴、综合社会调查、高校实验室科研项目数据以及全样本内容分析的论文 ( 共 34 篇, 占比 29% ) 外, 大量的论文在研究中均使用了非概率样本。出于以下两方面的原因, 本文对于此类涉及非概率样本问题的文章不做过多的讨论: 一方面, 科研经费等现实条件的限制使得大部分社科类论文难以做到概率抽样。也就是说, 这一类的数据问题更多的是资金问题, 而非技术性的难点; 另一方面, 即使数据源为概率样本, 也并不代表内生性问题得以解决, 互为因果、遗漏变量等问题依然可能存在, 且样本的抽样问题本身就是产生选择性偏差的原因之一, 因此, 接下来本文将重点放在内生性问题上, 对 118 篇文献中较为典型的数据获取过程、变量关系等进行讨论, 并未将 “完全符合因果推断”作为案例的筛选标准。
( 一) 遗漏变量偏差 ( omitted variable bias)
遗漏变量是指一个或多个与解释变量相关的变量没有被引入统计分析模型的控制变量中, 而是以扰动项 ( 残差项) 的形式出现②。在存在遗漏变量的情况下, 模型中解释变量的参数估计是不一致的。通过下面这个例子来说明遗漏变量造成的内生性问题及其对参数估计的影响。
假设研究问题是 “微信使用对大学生社会资本的影响”并准备通过如下的标准OLS 模型来进行分析③:yi = α + β xi + εi 其中因变量 yi 为大学生的社会资本, xi 表示微信使用情况, 可以包括微信的使用历史、聊天频率等等各种关于微信使用情况的测量。在收回调查问卷后, 根据观测数据和回归方程 ( 7) , 发现 β^ 显著不为 0。根据以上实证结果, 并不能得到 “微信使用对大学生社会资本有显著性的影响”的结论:
由于一些与 xi ( 微信使用情况) 相关性很强的变量被遗漏到扰动项中, 就造成了在 ( 7) 中对 β 的估计是不一致的, 所以微信使用对大学生社会资本的显著性影响可能根本就不存在。比如, 有理由认为大学生对微信的使用情况与其专业密切相关。理工科, 尤其是名牌大学的理工科学生使用微信的频率很可能不如人文学科的学生高; 再比如, 家庭收入高的学生很可能更早地开始使用智能手机, 从而可能使用微信的历史更久。另外, 家庭收入本身就可能影响到学生的微信使用强度和他们所拥有的社会资本。当把这些与解释变量相关的变量归入误差项, 也就意味着 Cov( x, ε) ≠ 0 ,xi ( 微信使用情况) 存在内生性。当用一个出现遗漏变量的回归方程 ( 7) 来进行参数估计时会出现:εi = β2 zi + νi
其中 zi 为被 ( 7) 中的遗漏变量。用 OLS 来估计 ( 7) 中的 β , 会有:plim β^ OLS( 7) = β1 + β2 Cov( x, z)Var( x) ( 8
有理由认为大学生的家庭收入与其拥有的社会资本是正相关的, 即 β2〉0 ; 家庭收入与大学生对微信的使用情况同样也应该是正相关的, 即 Cov( x, z) 〉0 。因此, 在出现这种遗漏变量的情况下, 依据观测数据和回归方程 ( 7) 估计到的微信使用对社会资本的影响, β , 包括了遗漏变量对社会资本的影响。这个估计值要大于其真实的影响 β1 。也就意味着微信使用对大学生社会资本的显著性影响可能并不存在。事实上, 从 ( 8) 式也可以看出, 只要与解释变量相关的遗漏变量存在, 通过 OLS 模型得到的参数估计就与总体是不一致的。
在使用观测数据的情况下, 遗漏变量是很难完全避免的一个问题。对于可以观察到的变量, 比如家庭收入、专业等等, 研究者们尽可能地把这些 “好”的控制变量引入回归方程即可。但是, 对一些不可直接观测的变量, 比如学生的性格等, 同样也可能与社交软件的使用情况密切相关, 就需要其他的方法来避免内生性造成的参数估计的不一致性。
( 二) 选择偏差 ( selection bias)
选择偏差主要包括自选择偏差 ( self-selection bias) 和样本选择偏差 ( sampleselection bias) 。这两种选择偏差都是内生性问题的特殊情况。
样本选择偏差是指样本的选择本身不是随机产生的, 非随机的样本不能反映总体的特征, 通过这些选择偏差的样本得到的参数估计也就与总体的真实值不一致。样本选择偏差表面看起来很容易避免, 但是在新闻传播学的研究中又非常容易出现。比如前文中所举的从业体验与新闻从业者的职业承诺的例子①, 该研究“采用滚雪球抽样的方法, 通过填答付费的形式在各个新闻从业者微信群、QQ群、微信朋友圈等渠道推广问卷网页链接获取样本”。在这个调查样本中, 研究者无法观测到那些离开新闻行业已经转入其他行业工作的个体, 尤其是如果转入其他行业的原新闻从业人员本身就是因为从业体验离开的。因此, 该文中采集到的样本就是一个有样本选择偏差的样本。使用这样一个样本来进行参数估计会大大低估从业体验的影响。实际上, 在网上发布某项调查问卷, 然后通过微信群、QQ群、微信朋友圈等渠道来收集到的样本本身就没有随机性, 存在样本选择问题。因为有大量的总体人口不在那些微信群、QQ 群、微信朋友圈, 甚至还有许多人根本不使用互联网。
自选择偏差是指处置变量 ( 解释变量) 不是随机分布于个体, 而是个体选择的结果。这个个体自我选择的过程会导致研究者使用样本进行的参数估计产生偏差。在新闻传播学研究中, 无论是存在自选择偏差还是样本选择偏差, 都无法得到一个随机样本。当研究者观察一个处置变量 X 对因变量 Y 的影响时, 由于 X 并非随机而是在某些约束条件下挑选出来的, 在回归方程中如果不对这种约束条件加以考虑而把它归入干扰项, 就会造成处置变量与干扰项相关。在文章的第三部分已经就选择性偏差问题做出了初步解释。这里再结合传播学研究的实例在潜在结果框架下针对自选择偏差及其后果做更详细的说明。
假设尝试探讨手机新闻使用对大学生政治知识的影响①。可以用一个二元随机变量 Ti = { 0,1} 来表示大学生是否使用手机阅读新闻, 用 Yi 表示大学生的政治知识水平。尽管没有观测到, 但可以设想一位经常用手机阅读新闻的学生假如没有使用手机阅读新闻的话,( 同样也可以设想一位没有使用手机阅读新闻的学生, 假如他使用了的话) 他的政治知识水平会是什么样的。因此, 对任意一位学生, 他的政治知识水平有两种潜在结果:
Yi=Y1i, if Ti = 1
=Y0i, if Ti = 0
= Y0i + ( Y1i - Y0i) × Ti
这里 Y1i 表示学生使用手机阅读新闻状态下的政治知识水平, 无论他是否真的使用手机阅读了新闻; 类似的, Y0i 表示学生没有使用手机阅读新闻状态下的政治知识水平, 无论他是否真的使用手机阅读了新闻。当使用调查数据时, 由于实际只能观察到一种结果, 所以只能比较观察到的两组学生在知识水平方面的平均差异。也就是:

如果可以随机地选择学生来用手机阅读新闻, 和不使用手机阅读新闻 ( 在这项研究中, 究竟什么是处理变量是有些含混不清的———是使用手机阅读新闻与用其他媒介阅读新闻的对比, 还是用手机阅读新闻与用手机但不用手机阅读新闻的对照。实际上, 在新闻传播学的准实验研究中, 同样存在许多类似的处置条件不明确的问题, 本文不再赘述) , 那也就意味着学生在政治知识方面的潜在结果独立于处置条件, 即 ( Y1i, Y0i) ⊥ Ti 。那么:
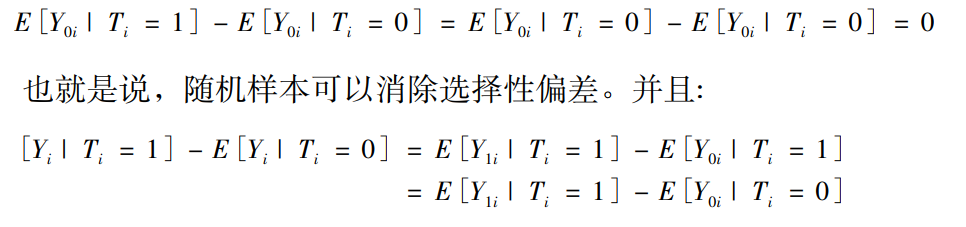
也就是说, 在随机样本的情况下, 观察到的组间平均知识水平差异就是所期望的平均处置效应或者平均因果效应 ( average treatment effect, ate) 。但是, 当使用的是调查得到的观测数据, 样本选择偏差 E[Y0i | Ti = 1] - E[Y0i | Ti = 0] 就很难再被解释为 0。一个最直观的问题就是那些喜欢用手机来阅读新闻的学生, 为什么喜欢用手机来阅读新闻, 如果没有手机的话他们是不是同样喜欢用其他媒体来阅读新闻?用手机阅读新闻的学生与不用手机阅读新闻的学生, 他们的差异仅仅在这一个点上吗? 一个合理的解释恰恰就是喜欢用手机阅读新闻的学生本身就喜欢阅读新闻, 而且很可能就是因为他们本来就具有更多的政治知识 ( 这种知识完全可以来自他处) ,所以才更喜欢通过各种媒体包括手机来阅读新闻。
由于存在选择性偏差, 通过调查问卷这类观测数据和普通的回归分析来研究媒体使用与个体的行为或态度之间的因果关系是非常困难的。比如通过调查问卷来检验中英文互联网的使用对留学生文化认同的影响①。很显然, 对美国文化更认同的学生经常上英文网站的概率会更大, 而对中国文化更认同的学生可能更经常使用中文互联网。这种基于非实验数据的关于个体行为与态度的研究, 能帮助研究者们发现相关性, 但很难进行因果关系推断。
( 三) 互为因果 ( simultaneity)
互为因果问题有时也被称为联立性问题或反向因果问题 ( reverse causality) , 即当因果推断中因变量也可以反过来解释自变量时, 该推断便存在互为因果问题。在社会科学中, 教育和收入可能是被用来说明互为因果问题的最广泛的一个例子。在世界范围内, 实证数据几乎都能发现更高的教育水平可以带来更可观的收入①, 即自变量 “教育”在一定的范围内对因变量 “收入”有着正面的影响。但同时, 因为教育资源的有限性、分布不均等特质, 拥有更高收入的人群更有可能获得更高水平的教育, 如资产相对丰厚的人才可能负担得起 MBA 和顶尖私立学校的学费, 即因变量“收入”对自变量 “教育”也具有影响力。
在新闻传播学领域, 有大量的研究涉及到媒体使用和个体的态度。媒体的接触自然有可能会影响个体的态度, 反过来个体的态度本身就可能影响其对媒介的选择。简单来说, 研究者们期望用某个外生的自变量来解释因变量, 而一旦因变量可以用以解释这个自变量, 形成互为因果, 原本应该是外生的自变量显然就被内生化了, 也就会与残差项产生关联并导致内生性问题。例如当研究 “乡村居民社交网络使用与人际交往”时②, 理论上社交网络的使用当然可能会影响个体的人际交往,但是人际交往本身又很可能对社交网络的使用产生影响。在这种典型的内生性问题面前, 观测数据和简单的 OLS 回归分析是无法帮助识别因果关系的。本文以此例做出进一步的说明: 假设 yi 表示个体的人际交往情况, xi 为个体的社交网络使用状况,则有:

当试图用简单回归方程 ( 9) 来估计 β1 时, 要求 Cov( xi, εi) = 0 , 这样才能得到个体的社交网络使用状况对其人际交往影响的一致性估计。但是在互为因果的情况下, 根据 ( 11) , Cov( xi, εi) ≠ 0 。所以此时 OLS 的参数估计是不一致的, 对于判断社交网络使用状况对人际交往的影响也就没有了参考意义。遗憾的是, 传播学领域中仍然存在这类互为因果的内生性研究。比如: 知识分享意向和知识分享行为③;主观感知与社交 APP ( 微信) 的使用①; 游戏中的英雄角色是否会影响玩家对真实历史人物的认知等等②。
( 四) 测量误差 ( measurement error)
在社会科学各个领域中, 变量测量中的缺陷一直备受关注, 即调查 ( surveyresults) 偏离 “那些真实反映 ( true reflections) 人口结果”的问题③。如在低收入人口的调查统计中④, 调查问卷中的语义表达、词汇运用、问题顺序与结构或是填答问卷时的环境等因素都有可能影响受访者对问题的理解以及填答时的心态, 从而影响研究者获取变量的调查值; 对于受访者而言, 他们在回答的过程中也可能存在不愿意透露信息、针对社会敏感性话题不愿表达真实想法等问题; 采访或实验设计中的具体环节, 如不同采访者在不同访谈场次中的表达、能力、个人特征的不同、实验中刺激的不同等都会对数据获取产生影响, 致使所测量数据与理想中的变量值不完全相符, 影响参数估计的一致性和因果关系的推断。
测量误差包括因变量的测量误差和解释变量的测量误差, 但因变量的测量误差一般不会影响参数估计的一致性。因为通常的假设是因变量的测量误差与解释变量是独立的, 这也就意味着回归方程的扰动项与解释变量是不相关的。所以因变量的测量误差通常不会导致内生性问题。假设在下面这个简单 OLS 模型中:

根据 OLS 的假设, E( εi) = E( μi) = 0 , Cov( xi, εi) = 0 , 如果 y* i 的测量误差与解释变量和方程扰动项误差无关, 那么 Cov( xi, μi) = 0 , Cov( εi, μi) = 0 。显然, 此时回归方程 ( 13) 和 ( 14) 都会给出一个 β 的一致无偏估计。但是由回归方程 ( 12) :

所以因变量的测量误差虽然不影响参数估计的一致性, 但会导致参数估计值的方差变大, 而当解释变量存在测量误差时就无法得到参数的一致性估计。一般而言,定量分析中都更关注回归方程能否给出一个一致性的估计, 所以测量误差通常指的就是回归模型使用到的解释变量的数值和解释变量的真实值之间的误差。就产生的过程来看, 该误差往往与自变量本身相关, 且在计算中往往会被视为随机误差而被归入残差项中, 并导致所观测的自变量与残差项相关, 引发内生性问题。假设在下面这个简单 OLS 模型中,

也就是说, 解释变量存在测量误差时会引发内生性问题, 而且此时简单的 OLS回归模型无法提供一个一致性的估计。回到上文所提及的 “社会敏感性话题”调查的问题, 如探究对某类群体的偏见 ( 地域偏见、性别偏见、种族偏见等) 的影响时,在受访者评估自己的偏见态度水平时, 可能会存在为了保持 “政治正确”而隐瞒自己真实态度的情况, 观察数据就会较真实情况而言更积极, 该态度差距即为偏差 vi ,且其与观察数据 “态度”xi 相关联, 所以当此差距在回归运算中被计入到残差项时,“态度”xi 便有一部分会源自内生。
总体而言, 测量偏差可分为两种: 一种聚焦于观察变量与非观察变量①, 观察变量的测量偏差问题指的是受访者的反馈偏离研究者所关注的测量值, 这种测量偏差可能源自数据获取过程中的每一个元素, 如问卷设计、受访者、调查者等, 以及数据的收集模式设计与方法等; 非观察变量的偏差指的是由于对样本的某些部分缺乏测量而产生的误差, “覆盖率、无响应 ( 单位和项目均无响应) 和抽样”是其产生的主要原因。
另一种指的是 “均值平方偏差”, 即方差与偏差的平方的和②, 其中方差是与调查的特定实施相关联的变量偏差的度量, 如问题的具体提问语句或采访者的具体人选, 该变量的可重复性是准确测量的关键要素, 若在不同访谈场次中提问语句有变,那么调查的提问环节会存在额外的方差。偏差则是指在一组确定的必要调查条件下,影响调查全过程的偏差, 是一种恒定的偏差 ( Hansen, M. et al. ) ③。如在自变量 “教育”与因变量 “收入”间的多元回归方程中, “能力”常被视为一个重要的自变量列入其中, 但 “能力”概念很难通过两三项数据完整地量化出来, 可能会被总体地低估或高估, 这种未能完整表达的偏差便是一种恒定的偏差, 贯穿调查的全部实施过程。
在传播学领域中, 测量偏差问题也很常见: 在政治传播领域中, 如何完美地衡量线上政治参与、线下政治参与以及互联网使用深度等是一个巨大的难题。尽管有众多学者提出了相应的测量项目, 如通过测量 “参加政治会议、集会或演讲”、“为政治候选人或政党工作”、 “为政治活动捐款”项目量表来具化 “线下政治参与程度”( Gil de Z iga, H. et al. ) ④; 以八个二分项 “衡量受访者在过去两年中是否参加过与政治有关的会议; 是否给报纸编辑写信或参加公共事务广播谈话节目; 是否为某一候选人或议题散发请愿书; 是否为某一当选官员投票; 是否为某一政治活动工作; 是否与某一公职人员联系; 是否召集其他人为某一政治组织筹集资金; 是否为某一政治组织或候选人捐款”来衡量受访者的政治参与情况 ( Hardy, B. W. etal. ) ①。可见, 在将某些概念转化为数据的操作化进程中还存在着很多模糊的问题:一, 程度量表与二分量表所包括项目是否能真实无差别地反应变量概念? 二, 不同国家、文化、地域的学者在相互探讨、引用、借鉴彼此的量化方法时, 这些方法是否真的能跨越政治文化的差距而起到效用? 答案是不能或者是很难。这便是 “均值平方偏差”所指的问题, 因为概念难以被完全地量化而导致的测量偏差。
同时, 传播学中也不缺少观察变量类的测量偏差, 如大多数研究者采用的调查问卷这一数据获取方法, 就问卷调查本身而言, 问卷可以保证每一位受访者每一次所遇到的问题是完全相同的, 不会产生额外的方差, 但同时, 自填的问卷难以保证受访者的认真程度, 如有以大陆多所高校学生为受访者的调查研究②, 其问卷的成功回收率仅有 32% , 那么该 32% 成功回收的问卷的有效性与真实性也可能会受到质疑; 就受访者而言, 其可能会因为担心隐私泄露而勾选非真实的选项, 或是基于身份原因选择更 “正确”的答案。如在对留美的中国留学生的本国文化认同的问卷中③, 在描述性统计部分研究者得到了一个积极的文化认同结果, 但该类问题的设置本身就很难得到一个无偏的答案。
但值得了解的是, 自填问卷的认真程度难以得到保障这一问题并不会通过转变为指导性填答而得到解决, 因为即便指导者可以使问卷的语义、目的更清晰地呈现给受访者, 督促受访者更认真地对待此次填写, 但不同的指导者、同一指导者的不同状态与穿着也都可能会影响到受访者的填答, 所以观察变量的测量偏差也很难得到解决。
五、讨论
随机实验通常被认为是识别变量之间是否存在因果关系的最值得信赖的方法。但是在社会科学, 尤其是在新闻传播学中, 进行各类实验和准实验方法往往需要投入大量的资金、要受道德伦理的约束, 经常还需要一些运气成分甚至有时候根本不可能进行④。所以在现实的科研活动中, 新闻传播学领域大量有价值的研究不得不依赖非实验数据展开。使用观测数据来进行因果关系推断, 比如识别媒体使用和个体行为或态度之间的因果关系时, 一个难以避免的问题就是数据的内生性问题, 也就是解释变量和残差项相关。在 “观测数据———回归分析”的研究模式下, 内生性对因果关系造成的影响通常无法被有效剔除。这样一来, 回归模型所得出的参数估计就与总体不一致。这些观测数据虽然可以帮助研究者们检验变量间的相关关系, 但是也经常需要更精巧的研究设计来更进一步地识别变量间的因果联系。
本文通过对近年来新闻传播学领域使用的定量研究方法教材以及采用量化方法的科学研究论文进行回顾, 发现处理 “内生性问题”可能会成为未来传播学定量研究的重要内容之一。文章采用代表性较强的 “在调查数据 ( survey data) 的基础上使用多种回归方法并做出因果推断”的研究为 “定量研究”的主要讨论对象、以普通最小二乘法 ( ordinary least squares) 为主要分析模型, 以新闻传播学中的经典变量关系为案例, 对什么是内生性问题、相关关系与因果关系的区别、内生性问题对因果推断产生的影响, 以及形成内生性问题的原因进行了深入介绍和探讨。值得注意的是, 目前在新闻传播学领域的不少研究都是通过增减模型中的解释变量并观察回归方程给出的 R2 的变化来验证解释变量对因变量的影响。此类方法只能检验解释变量和因变量之间的相关性, R2 的变化本身并不能说明变量之间有或没有因果联系。
必须指出的是, 尽管内生性问题是对新闻传播学研究中因果关系识别的严重威胁, 但这并不意味着以 “观测数据———回归分析”为研究模式的相关关系研究是没有意义的。相反, 许多关于变量之间的相关性定量分析是积极的, 也是十分必要的。在因果分析条件难以满足的情况下, 很多变量间的相关关系研究可以成为日后因果分析的基础, 可以凭借相关性的可预测性而成为政策制定的有力论据, 还可以对具体的学科实践提供依据。例如 “观看暴力影视”和 “校园霸凌行为”这两个变量间的关系。要进行因果关系推断就需要剔除内生性问题的影响、保持变量外一切要素不变等条件。这对于社会性较强, 且难以进行实验的 “观看暴力影视”和 “校园霸凌行为”等变量而言难度太高了, 所以很难得出规范合理的因果关系。但这并不表明两者间可能的相关关系是无意义的, 在 “观看暴力影视”与 “校园霸凌行为”正相关的情况下, 相关机构就可以以此为依据, 对暴力影视进行分级, 规定不同年龄段儿童可观看的暴力级别, 以减少校园暴力。
因此, 研究者们对因果关系的追寻并不抹杀相关关系的探索与实践意义。不过,新闻传播学学科的发展也确实需要进一步探讨诸如媒体使用与个体的态度和行为之间的因果联系。基于此, 本文建议改进研究方法课程的内容, 将处理传播学研究中遇到的内生性问题视作未来学科教学和科研的一个发展方向, 并在此给出三点具体建议:
一、加强各类实验方法, 包括调查实验 ( survey experiment) , 田野实验 ( fieldexperiment) 包括自然实验 ( natural experiment) ) 和实验室实验 ( lab experiment) 的教学和科研应用。提升数据质量, 尽可能获取更 “完美的”数据是检验理论假说最有效的途径之一。各种实验和准实验方法可以从数据源头入手, 通过完美的实验设计等方法来解决内生性问题背后的本质难题———在获得样本数据时无法保持其他条件完全不变, 无法独立考量处置变量的影响等等。当然, 实验法也具有一些需要额外考量的因素, 如实验所需要的物质支持; 实验所需要遵守的道德伦理标准, 有一些挑战伦理的实验只能停留于想象层面; 实验所需要的运气, 如自然实验的发生时间、地点等, 具有一定的巧合与偶然性。
二、在无法应用各类实验方法的情况下, 基于 “观测数据———回归推断”的模式, 可以考虑新的研究设计方案, 对非实验数据进行更有效的识别。比如使用断点回归分析 ( regression discontinuity) 、双重差分模型 ( difference in difference) 和工具变量 ( instrumental variable) 等方法来尽可能的剔除内生性问题的影响, 即运用调查数据模拟真实实验来获得接近真实情况的因果关系①。
三、强化新闻传播学的学科理论构建。在有效的研究设计基础上的定量研究,无疑会帮助新闻传播学检验和构建学科理论。但是理论逻辑本身也是指导实证研究的重要依据。强大的理论支撑和有效的研究设计, 会使回归变得更有意义。正如肯德尔 ( Kendall) 和斯图亚特 ( Stuart) 所说: “一个统计关系式, 不管多强也不管多么有启发性, 永远不能确立因果方面的联系: 对因果关系的理念, 必须来自统计学以外, 最终来自这种或那种理论。”②
本文为我们研究方法系列论文的第一篇, 重点讨论了新闻传播学定量研究中的内生性问题。在后续论文中, 我们将分别从 “实验和准实验”、“基于观测数据的研究设计”、“实证研究与理论构建”和 “‘好的’控制变量”等方面为主题来进一步探讨如何解决内生性问题以及新闻传播学中研究方法方面的其他重要问题。
随机实验 ( 包括各种准实验) 通常被认为是识别变量之间因果关系的最值得信赖的方法。然而, 在新闻传播学领域的研究中, 因受资金、规章和伦理等条件的制约, 科研人员经常不得不使用非实验数据 ( nonexperimental data) 来从事科研活动①,通过这些观测数据 ( observational data) 或者回顾数据 ( retrospective data) 来进行因果推断则是一项颇具挑战性的工作②。其中一个主要的原因就是观测数据基本上都带有与生俱来的内生性问题 ( endogeneity) , 也就是解释变量和误差项的相关性问题。内生性问题会造成回归方程中参数估计的不一致性, 是研究人员进行因果关系识别和理论构建的巨大障碍。因此, 在潜在结果框架下对这些问题的处理, 也成了社会科学现代定量研究方法教学和应用的核心问题之一。
而从当前的教学和科研情况来看, 传播学研究方法类流行教材中定量部分的相关内容将重点更多地放在了如何来收集观测数据, 以及如何利用此类数据进行回归分析和统计学意义上的显著性推断上。在主流的新闻传播学期刊上, 典型的应用定量方法进行因果关系推断的论文也基本上都遵循了 “观测数据———回归分析”的模式。而这种研究模式对观测数据的策略性识别以及对内生性问题的处理方面仍有提升的空间。在无法剔除内生性影响的情况下, 直接通过观测数据来进行统计推断,并根据统计学上的显著性水平来进行因果关系推断和理论构建的难度比较大。
从 2018 年至 2020 年 11 月, 新闻传播学领域的传统四大期刊包括 《新闻与传播研究》、《国际新闻界》、《新闻大学》和 《现代传播》共发表了基于非实验数据的定量分析方法类论文 210 篇, 其中涉及到因果关系推断的论文共 118 篇, 占比约为56% ②。此 118 篇论文均存在内生性问题③, 其中存在遗漏变量偏差的论文共 118 篇( 占比 100% ) 、选择偏差共 92 篇 ( 占比 78% ) 、互为因果共 33 篇 ( 占比 28% ) 、测量误差共 111 篇 ( 占比 94% ) , 同一篇论文内常会出现多种内生性问题, 而其中仅有一篇文献讨论了数据的内生性问题并尝试使用工具变量法 ( instrumental variableapproach) 来尽量减小各类偏差对因果关系的威胁④。可见, 内生性问题一直都普遍地存在于传播学领域的研究当中, 并未得到有效的解决, 这也一定程度上说明了本篇文章所要探讨的问题的重要性与必要性。
事实上, 在 “观测数据———回归分析”模式下发现的解释变量和因变量 ( 被解释变量) 之间统计学意义上的显著性关系, 往往只是相关关系, 而这些相关关系通常可以通过非控制性质的研究直接得到①。要对因果关系假说进行实证检验, 从相关关系进步到因果关系, 在非实验条件下, 还需要研究人员思考相应的研究设计, 并对数据进行更多的识别和进一步处理, 以剔除内生性问题的影响。当然, 除了对数据的识别以外, 构建变量间的理论联系也极为重要, 不仅能帮助我们有效地建立起对应的逻辑关系, 也有助于我们重新思考实证分析的结果和研究的过程。这一点,也常常被众多的定量研究论文所忽略。接下来, 本文首先讨论目前新闻传播学研究方法类流行教材中关于定量部分的内容, 以及在传播学研究中使用非实验数据进行因果推断的主要模式。
二、定量研究方法在新闻传播学中的应用问题
“研究方法服务于研究问题与研究目的”是科研人员的共识, 如何使用定量方法要取决于研究的具体目的, 若目的是观察变量之间的相关关系, 那么尽可能地增加样本对其而言更为重要; 若目的在于使用量化数据来进行因果关系推断, 那么研究的重点和难点并不在定量方法本身, 而在于如何来设计此项研究以合理地运用数据, 解决内生性造成的参数估计不一致性以及这种影响对理论结论的干扰。而新闻传播学的研究往往更多的是基于观测数据来探讨变量间的因果关系②, 因此, 为了排除数据的内生性干扰, 研究设计 ( research design) 是新闻传播学定量研究中极其重要的一环。
如在媒体建构与民众的社会公平感的变量关系中③, 研究者无法通过 “观测数据——统计推断”的定量分析方法验证核心论述——“民众的社会公平感是社会媒体建构和社会建构的结果”, 因为这样的论述和基于的分析模式几乎面临着来自内生性问题的各个方面的挑战。比如, 社会为什么会形成目前的媒体建构, 或者说目前的媒体建构是如何形成的? 几乎没有人会认为一种社会媒体建构的出现是一个随机过程, 那么一个潜在的合理解释便是这种媒体建构源自于民众 ( 所需要) 的社会公平感, 即社会公平的需要促成了当前的媒体建构形式, 而非后者决定了前者。所以,在逻辑上 “民众的社会公平感是社会媒体建构和社会建构的结果”这个核心论述就存在着互为因果的最为典型的内生性问题———原本假设是纯外生变量的媒体建构实际上却是一个被因变量决定着的内生变量。更近一步的, 社会为什么会同时形成目前的媒体建构和民众的社会公平感? 一个潜在的合理解释是这种结果是受到了社会政治制度的影响。于是政治制度便作为一种混淆变量 ( confounding variable) 同时影响了 X 和 Y。其他的内生性问题如选择偏差和测量误差等同样可能威胁到以上所说的核心论述。所以, 在回归分析中所发现的 X 和 Y 之间的关系很可能并不是因果关系。更严格地讲, 在这一类基于 “观测数据———统计推断”的传播学研究中所得到的参数估计, 与总体实际的参数经常是不一致的。因此, 这种定量研究设计思路对新闻传播学理论构建的帮助作用还有可商榷之处。
由上例可知, 为了探究民众的社会公平感是否会受到社会媒体建构和社会建构的影响, 真正的重点和难点并不在于如何收集观测数据以及进行某种形式的回归分析, 而在于如何设计一个有针对性的研究方案, 使得具有内生性的社会媒体建构和社会建构这些解释变量至少可以部分地外生化。在无法采用实验或准实验方法的情况下, 无法真正随机分配解释变量, 所以能否成功地采用一种基于观测数据的研究设计以尽量避免内生性问题是研究成败的关键。
目前在新闻传播学流行的研究方法教材中和主流期刊上, 在如何处理观测数据带来的内生性问题等方面, 仍然有较大的改进余地。目前方法类教材的量化研究方法重点在于如何得到观测数据, 以及如何进行推断统计上, 而对研究设计以及数据识别策略等处理内生性问题的各类方法介绍得还不够全面。类似的, 近年来在新闻传播学领域, 大多数的定量论文都采取了 “观测数据———回归分析”的模式来进行因果关系推断。同样也缺少了数据识别策略部分。绝大多数论文都未提及、未解决调查数据所存在的内生性问题。下面以一个具体的例子来进一步说明究竟什么是内生性问题以及它会对传播学的定量研究造成什么样的影响。
在 “哪些因素影响了新闻从业者的职业承诺”这一问题上, 研究者认为是从业体验等因素对新闻从业者的职业承诺水平产生了显著影响①。其通过问卷调查得到了yi = α + β xi + γ zi + εi ( 1) 在 ( 1) 式中, yi 为因变量, 表示新闻从业者的职业承诺。显然, 由于 yi 是要被模型决定的, 所以 yi 是内生的 ( endogenous) 。xi 是研究所感兴趣的解释变量, 新闻工作者的从业体验。在进行参数估计时, xi 必须是外生的 ( exogenous) , 即由模型以外的其他因素所决定的。zi 是一些控制变量包括年龄、性别、教育水平等; εi 为模型相关的残差项。
当高斯 - 马尔科夫定理 ( gauss-markov theorem) 成立时, 利用 ( 1) 式和调查数据就能得到 β 的最佳线性无偏估计 ( best linear unbiased estimator, blue) , β^ 。值得注意的是, 如果 xi 确实是一个外生变量, 那么利用 OLS 得到的 β^ 就是一致的。也就是说, 这种情况下如果调查取得的样本量比较大, 估计出的参数会趋近于总体的真实参数。但是, 如果 xi 是与残差项 εi 相关的, 那么此时 xi 就不再是一个外生变量, 而是具有了内生性的变量。这种情况下直接通过 OLS 回归分析得到的参数估计就是不一致的①。如果参数的样本估计值与总体的真实值之间不具有一致性, 那么该回归分析对变量间因果关系识别和进行理论构建的帮助是比较有限的。
回到新闻从业者的职业承诺的例子。解释变量 xi , 新闻工作者的从业体验, 很显然不会是一个随机取值的变量②。比如它很可能跟个体的收入和职务有关; 也很可能与工作单位的类型, 比如央视、人民日报还是县级融媒体中心等因素有关。在回归模型 ( 1) 中, 这些与解释变量相关的变量被归入残差项后, 得到的新闻工作者的从业体验对其职业承诺的参数估计就极可能是一个非一致的估计, 所谓的显著性影响很可能只是表面上的相关性。
总之, 内生性问题在新闻传播学研究中广泛存在。在使用非实验数据比如社会调查数据的情况下, 内生性问题是进行因果关系推断的巨大障碍。因为此时无论采用什么形式的回归分析技术, 所得到的回归显著性均不能推断出变量间的因果关系,一般只能识别解释变量和被解释变量之间的相关关系。接下来, 在分析了相关关系和因果关系之间的联系与区别后, 本文将借助实例来重点讨论形成新闻传播学领域中观测数据内生性的主要原因。
三、新闻传播学研究中的相关关系和因果关系
在定量研究和统计学中, 相关性或者相关关系 ( correlation) 指的是两个随机变量之间的线性相关关系③。相对而言, 因果关系的定义要比相关关系复杂一些。在现代社会科学中, 被广泛接受的因果关系的概念是建立在潜在结果框架 ( framework of potential outcomes) ①, 或者也被称为 Rubin 因果模型 ( rubin causal model, RCM) 基础上的②。RCM 因果模型中有三个基本构成部分: 潜在结果 ( potential outcomes) 、分配机制 ( assignment mechanism) 和个体稳定性假设 ( the stable unit treatment valueassumption, sutva) 。在 RCM 模型下, 因果关系效应 ( causal effect, 或者干预 /处置效应 treatment effect) 被识别为对于任何一个个体, 有无干预或者处置 ( treatment)在两个潜在结果之间的差别。当然, 实际的定量研究所关注的焦点是对于两组个体,有无干预在两个潜在结果之间的平均因果效应 ( average treatment effect, ate) 。
在实际的科研活动中, 科研人员并非总是使用线性回归模型 ( 或单纯的线性相关关系) 来辅助进行因果关系推断。但是: 第一、使用其他模型比如 Logistic 或者Probit 等回归模型所发现的统计学意义上的显著性, 在多数情况下使用 OLS 模型同样可以得到。第二、从 OLS 模型到因果关系推断之间面临的主要困难 ( 内生性问题) 在其他模型中同样存在。为了简便而不失一般性地说明问题, 本文接下来对所有用于说明性质的回归方程都统一使用 OLS 模型。
定量研究中得到的相关关系并不意味着因果关系 ( correlation does not imply causation) ③。但是在新闻传播学的研究中, 仍然存在通过使用相关性的研究设计总结出因果性结论的研究。在这些研究中只存在验证解释变量和因变量之间相关性的设计, 而没有任何能够说明因果关系的设计。例如, 假设研究问题是 “政治相关新闻的接触, 是否会对政治参与行为产生影响”④, 当使用以下标准的 OLS 模型来进行推断时:yi = α + β xi + εi 内生的因变量 yi 为政治参与行为, xi 表示政治相关新闻的接触, εi 仍是模型的残差项。回归系数 β^ 可以用向量形式表示如下:β^ = ( X'X) -1X'Y 即使回归系数 β^ 是非常显著的不等于 0, 依然无法得到政治相关新闻的接触会对政治参与行为产生影响的因果性结论。因为依据 β^ ≠ 0 得出因果关系的前提是 ( 2)本身必须包括因果效应的解释⑤, 而这一点显然不满足。理论上当然有理由认为政治相关新闻的接触可能会对政治参与行为产生影响。但是, 同样也有理由认为政治参与行为本身就会影响人们对政治新闻的接触。当把 ( 2) 中 xi 和 yi 的位置互换后再重新进行 OLS 回归分析, 会得到完全一样的结论。这种 OLS 回归方程本身并不能得出与因果关系有关的信息。目前新闻传播学领域的一些研究都是通过增减模型的解释变量并观察回归方程给出的 R2 的变化来验证解释变量对因变量的影响。这种设计通常只能检验解释变量和因变量之间的相关性, R2 的变化本身并不能说明变量之间有或没有某种因果联系。关键的问题是, 即便假定相关新闻的接触对每一个个体的影响是相同的, 不会存在个体上的差异, 仍难相信每个个体对政治相关新闻的接触是随机的。换句话说, xi 并不是一个外生变量, 它可能与个体的政治态度相关, 与个体以往的政治参与行为等等很多形成内生性的因素有关。当把这些因素归入随机误差后, 回归系数 β^ 所包含的信息远远多于 “政治相关新闻的接触对政治参与行为产生影响”。
而在潜在结果框架下, 一个 OLS 模型可以得到一个因果效应的解释: 假设一个因果关系问题 “社交媒体中的社交使用对青年的个人信息权意识有促进作用”①。为简单并说明问题起见, 这里假定社交 APP 有两种使用方式, 一种是社交使用, 另一种是非社交使用②。进一步的定义干预变量是 APP 的社交使用情况并用 T 表示干预状态。对于任意的个体 i 存在两种干预状态, 其中 Ti = 1 表示个体 i 社交使用该 APP,Ti= 0 表示个体 i 非社交使用该 APP。用 Y1i 表示个体 i 在状态 Ti = 1 下的个人信息权意识, Y0i 表示个体 i 在状态 Ti = 0 下的个人信息权意识。那么观测结果可以用潜在结果的形式表示成:Yi= α + τATE Ti + εi 其中: α = E[Y0], τATE = E[Y1] - E[Y0],误差项εi = ( 1 - Ti) × ( Y0i - E [Y0i]) + Ti × ( Y1i - E [Y1i]) τATE是平均干预效果, 或者平均因果效应。
( 4) 式虽然在表面形式上与 OLS 相同, 但其表示的是处置变量与潜在结构间的因果关系, 并非 OLS 模型。控制组和实验组的结果均值, 也就是青年的个人信息权意识的平均值在社交使用和非社交使用 APP 时分别为:
| E[Yi | Ti = 1] = α + τATE + E[εi | Ti] 以及: E[Yi | Ti = 0] = α + E[εi | Ti] |
现在假 定 APP 的 社 交 使 用 与 青 年 个 人 信 息 权 意 识 之 间 的 条 件 期 望 函 数( conditional expectation function, cef) 满足线性关系。如果想利用 ( 2) 式中 OLS 的回归系数来做因果效应解释, 那么回归系数 β^ 就应该等于 ( 5) - ( 6) 。也就是:
β^ = E[Yi | Ti = 1] - E[Yi | Ti = 0]
= τATE + { E[Y0i | Ti = 1] - E[Y0i | Ti = 0]}
+ ( 1 - p) { E[Y1i - Y0i | Ti] 1 = - E[Y1i - Y0i | Ti = 0]}
其中 p 是任意一个青年个体在控制组中的概率, 也可以理解为控制组成员所占的比例。显然, 要使用 OLS 的回归系数 β^ 来解释潜在结果模型中的因果关系必须满足两个条件①:
条件一: E[Y0i | Ti = 1] - E[Y0i | Ti = 0] = 0 。即每个个体在 APP 的社交使用和非社交使用中不能存在选择偏差。
条件二: [Y1i - Y0i | Ti = 1] - E[Y1i - Y0i | Ti = 0] = 0 。即 APP 的社交使用对个人信息权意识的影响在每个个体上不会出现差别。
回到案例中, 在使用观测数据的条件下, 条件一很难得到满足: 是什么原因导致了有的年轻人使用 APP 的社交功能, 而其他人使用了 APP 的非社交功能? 很难相信每一个年轻人使用什么样的社交媒体或者使用社交媒体的哪一部分功能完全是随机的。那么导致年轻人使用 APP 的某些功能的原因会不会本身就是影响他们个人信息权意识的原因 ( 一个混淆变量) ?
在潜在结果框架下, 同时满足以上两个条件的一个充分条件是年轻人的个人信息权意识的潜在结果独立于社交媒体的使用, 也就是满足条件独立假设 ( conditional
| independence assumption, cia) ②,( Y1i | 。根据潜在结果模型展开的研究设计 |
四、新闻传播学定量研究中的内生性问题
实验方法无疑是进行因果推断最为有效的方法。但是在社会科学, 尤其是在新闻传播学的研究中, 更多的情况下, 研究人员只能依据观测数据来发现因果关系。在非实验数据条件下, 解释变量与残差项之间出现相关性的内生性问题很容易发生,从而导致参数估计的不一致性, 无法有效地帮助识别解释变量和因变量之间的因果联系。在这一节, 本文仍然通过新闻传播学中的实例来说明在使用观测数据进行因果关系推断时经常会遇到的四种内生性问题。值得注意的是, 当使用非实验数据时,多种形式的内生性问题经常会同时出现在一项研究中①。
需要说明的是, 除了部分使用国内统计年鉴、综合社会调查、高校实验室科研项目数据以及全样本内容分析的论文 ( 共 34 篇, 占比 29% ) 外, 大量的论文在研究中均使用了非概率样本。出于以下两方面的原因, 本文对于此类涉及非概率样本问题的文章不做过多的讨论: 一方面, 科研经费等现实条件的限制使得大部分社科类论文难以做到概率抽样。也就是说, 这一类的数据问题更多的是资金问题, 而非技术性的难点; 另一方面, 即使数据源为概率样本, 也并不代表内生性问题得以解决, 互为因果、遗漏变量等问题依然可能存在, 且样本的抽样问题本身就是产生选择性偏差的原因之一, 因此, 接下来本文将重点放在内生性问题上, 对 118 篇文献中较为典型的数据获取过程、变量关系等进行讨论, 并未将 “完全符合因果推断”作为案例的筛选标准。
( 一) 遗漏变量偏差 ( omitted variable bias)
遗漏变量是指一个或多个与解释变量相关的变量没有被引入统计分析模型的控制变量中, 而是以扰动项 ( 残差项) 的形式出现②。在存在遗漏变量的情况下, 模型中解释变量的参数估计是不一致的。通过下面这个例子来说明遗漏变量造成的内生性问题及其对参数估计的影响。
假设研究问题是 “微信使用对大学生社会资本的影响”并准备通过如下的标准OLS 模型来进行分析③:yi = α + β xi + εi 其中因变量 yi 为大学生的社会资本, xi 表示微信使用情况, 可以包括微信的使用历史、聊天频率等等各种关于微信使用情况的测量。在收回调查问卷后, 根据观测数据和回归方程 ( 7) , 发现 β^ 显著不为 0。根据以上实证结果, 并不能得到 “微信使用对大学生社会资本有显著性的影响”的结论:
由于一些与 xi ( 微信使用情况) 相关性很强的变量被遗漏到扰动项中, 就造成了在 ( 7) 中对 β 的估计是不一致的, 所以微信使用对大学生社会资本的显著性影响可能根本就不存在。比如, 有理由认为大学生对微信的使用情况与其专业密切相关。理工科, 尤其是名牌大学的理工科学生使用微信的频率很可能不如人文学科的学生高; 再比如, 家庭收入高的学生很可能更早地开始使用智能手机, 从而可能使用微信的历史更久。另外, 家庭收入本身就可能影响到学生的微信使用强度和他们所拥有的社会资本。当把这些与解释变量相关的变量归入误差项, 也就意味着 Cov( x, ε) ≠ 0 ,xi ( 微信使用情况) 存在内生性。当用一个出现遗漏变量的回归方程 ( 7) 来进行参数估计时会出现:εi = β2 zi + νi
其中 zi 为被 ( 7) 中的遗漏变量。用 OLS 来估计 ( 7) 中的 β , 会有:plim β^ OLS( 7) = β1 + β2 Cov( x, z)Var( x) ( 8
有理由认为大学生的家庭收入与其拥有的社会资本是正相关的, 即 β2〉0 ; 家庭收入与大学生对微信的使用情况同样也应该是正相关的, 即 Cov( x, z) 〉0 。因此, 在出现这种遗漏变量的情况下, 依据观测数据和回归方程 ( 7) 估计到的微信使用对社会资本的影响, β , 包括了遗漏变量对社会资本的影响。这个估计值要大于其真实的影响 β1 。也就意味着微信使用对大学生社会资本的显著性影响可能并不存在。事实上, 从 ( 8) 式也可以看出, 只要与解释变量相关的遗漏变量存在, 通过 OLS 模型得到的参数估计就与总体是不一致的。
在使用观测数据的情况下, 遗漏变量是很难完全避免的一个问题。对于可以观察到的变量, 比如家庭收入、专业等等, 研究者们尽可能地把这些 “好”的控制变量引入回归方程即可。但是, 对一些不可直接观测的变量, 比如学生的性格等, 同样也可能与社交软件的使用情况密切相关, 就需要其他的方法来避免内生性造成的参数估计的不一致性。
( 二) 选择偏差 ( selection bias)
选择偏差主要包括自选择偏差 ( self-selection bias) 和样本选择偏差 ( sampleselection bias) 。这两种选择偏差都是内生性问题的特殊情况。
样本选择偏差是指样本的选择本身不是随机产生的, 非随机的样本不能反映总体的特征, 通过这些选择偏差的样本得到的参数估计也就与总体的真实值不一致。样本选择偏差表面看起来很容易避免, 但是在新闻传播学的研究中又非常容易出现。比如前文中所举的从业体验与新闻从业者的职业承诺的例子①, 该研究“采用滚雪球抽样的方法, 通过填答付费的形式在各个新闻从业者微信群、QQ群、微信朋友圈等渠道推广问卷网页链接获取样本”。在这个调查样本中, 研究者无法观测到那些离开新闻行业已经转入其他行业工作的个体, 尤其是如果转入其他行业的原新闻从业人员本身就是因为从业体验离开的。因此, 该文中采集到的样本就是一个有样本选择偏差的样本。使用这样一个样本来进行参数估计会大大低估从业体验的影响。实际上, 在网上发布某项调查问卷, 然后通过微信群、QQ群、微信朋友圈等渠道来收集到的样本本身就没有随机性, 存在样本选择问题。因为有大量的总体人口不在那些微信群、QQ 群、微信朋友圈, 甚至还有许多人根本不使用互联网。
自选择偏差是指处置变量 ( 解释变量) 不是随机分布于个体, 而是个体选择的结果。这个个体自我选择的过程会导致研究者使用样本进行的参数估计产生偏差。在新闻传播学研究中, 无论是存在自选择偏差还是样本选择偏差, 都无法得到一个随机样本。当研究者观察一个处置变量 X 对因变量 Y 的影响时, 由于 X 并非随机而是在某些约束条件下挑选出来的, 在回归方程中如果不对这种约束条件加以考虑而把它归入干扰项, 就会造成处置变量与干扰项相关。在文章的第三部分已经就选择性偏差问题做出了初步解释。这里再结合传播学研究的实例在潜在结果框架下针对自选择偏差及其后果做更详细的说明。
假设尝试探讨手机新闻使用对大学生政治知识的影响①。可以用一个二元随机变量 Ti = { 0,1} 来表示大学生是否使用手机阅读新闻, 用 Yi 表示大学生的政治知识水平。尽管没有观测到, 但可以设想一位经常用手机阅读新闻的学生假如没有使用手机阅读新闻的话,( 同样也可以设想一位没有使用手机阅读新闻的学生, 假如他使用了的话) 他的政治知识水平会是什么样的。因此, 对任意一位学生, 他的政治知识水平有两种潜在结果:
Yi=Y1i, if Ti = 1
=Y0i, if Ti = 0
= Y0i + ( Y1i - Y0i) × Ti
这里 Y1i 表示学生使用手机阅读新闻状态下的政治知识水平, 无论他是否真的使用手机阅读了新闻; 类似的, Y0i 表示学生没有使用手机阅读新闻状态下的政治知识水平, 无论他是否真的使用手机阅读了新闻。当使用调查数据时, 由于实际只能观察到一种结果, 所以只能比较观察到的两组学生在知识水平方面的平均差异。也就是:
如果可以随机地选择学生来用手机阅读新闻, 和不使用手机阅读新闻 ( 在这项研究中, 究竟什么是处理变量是有些含混不清的———是使用手机阅读新闻与用其他媒介阅读新闻的对比, 还是用手机阅读新闻与用手机但不用手机阅读新闻的对照。实际上, 在新闻传播学的准实验研究中, 同样存在许多类似的处置条件不明确的问题, 本文不再赘述) , 那也就意味着学生在政治知识方面的潜在结果独立于处置条件, 即 ( Y1i, Y0i) ⊥ Ti 。那么:
也就是说, 在随机样本的情况下, 观察到的组间平均知识水平差异就是所期望的平均处置效应或者平均因果效应 ( average treatment effect, ate) 。但是, 当使用的是调查得到的观测数据, 样本选择偏差 E[Y0i | Ti = 1] - E[Y0i | Ti = 0] 就很难再被解释为 0。一个最直观的问题就是那些喜欢用手机来阅读新闻的学生, 为什么喜欢用手机来阅读新闻, 如果没有手机的话他们是不是同样喜欢用其他媒体来阅读新闻?用手机阅读新闻的学生与不用手机阅读新闻的学生, 他们的差异仅仅在这一个点上吗? 一个合理的解释恰恰就是喜欢用手机阅读新闻的学生本身就喜欢阅读新闻, 而且很可能就是因为他们本来就具有更多的政治知识 ( 这种知识完全可以来自他处) ,所以才更喜欢通过各种媒体包括手机来阅读新闻。
由于存在选择性偏差, 通过调查问卷这类观测数据和普通的回归分析来研究媒体使用与个体的行为或态度之间的因果关系是非常困难的。比如通过调查问卷来检验中英文互联网的使用对留学生文化认同的影响①。很显然, 对美国文化更认同的学生经常上英文网站的概率会更大, 而对中国文化更认同的学生可能更经常使用中文互联网。这种基于非实验数据的关于个体行为与态度的研究, 能帮助研究者们发现相关性, 但很难进行因果关系推断。
( 三) 互为因果 ( simultaneity)
互为因果问题有时也被称为联立性问题或反向因果问题 ( reverse causality) , 即当因果推断中因变量也可以反过来解释自变量时, 该推断便存在互为因果问题。在社会科学中, 教育和收入可能是被用来说明互为因果问题的最广泛的一个例子。在世界范围内, 实证数据几乎都能发现更高的教育水平可以带来更可观的收入①, 即自变量 “教育”在一定的范围内对因变量 “收入”有着正面的影响。但同时, 因为教育资源的有限性、分布不均等特质, 拥有更高收入的人群更有可能获得更高水平的教育, 如资产相对丰厚的人才可能负担得起 MBA 和顶尖私立学校的学费, 即因变量“收入”对自变量 “教育”也具有影响力。
在新闻传播学领域, 有大量的研究涉及到媒体使用和个体的态度。媒体的接触自然有可能会影响个体的态度, 反过来个体的态度本身就可能影响其对媒介的选择。简单来说, 研究者们期望用某个外生的自变量来解释因变量, 而一旦因变量可以用以解释这个自变量, 形成互为因果, 原本应该是外生的自变量显然就被内生化了, 也就会与残差项产生关联并导致内生性问题。例如当研究 “乡村居民社交网络使用与人际交往”时②, 理论上社交网络的使用当然可能会影响个体的人际交往,但是人际交往本身又很可能对社交网络的使用产生影响。在这种典型的内生性问题面前, 观测数据和简单的 OLS 回归分析是无法帮助识别因果关系的。本文以此例做出进一步的说明: 假设 yi 表示个体的人际交往情况, xi 为个体的社交网络使用状况,则有:
当试图用简单回归方程 ( 9) 来估计 β1 时, 要求 Cov( xi, εi) = 0 , 这样才能得到个体的社交网络使用状况对其人际交往影响的一致性估计。但是在互为因果的情况下, 根据 ( 11) , Cov( xi, εi) ≠ 0 。所以此时 OLS 的参数估计是不一致的, 对于判断社交网络使用状况对人际交往的影响也就没有了参考意义。遗憾的是, 传播学领域中仍然存在这类互为因果的内生性研究。比如: 知识分享意向和知识分享行为③;主观感知与社交 APP ( 微信) 的使用①; 游戏中的英雄角色是否会影响玩家对真实历史人物的认知等等②。
( 四) 测量误差 ( measurement error)
在社会科学各个领域中, 变量测量中的缺陷一直备受关注, 即调查 ( surveyresults) 偏离 “那些真实反映 ( true reflections) 人口结果”的问题③。如在低收入人口的调查统计中④, 调查问卷中的语义表达、词汇运用、问题顺序与结构或是填答问卷时的环境等因素都有可能影响受访者对问题的理解以及填答时的心态, 从而影响研究者获取变量的调查值; 对于受访者而言, 他们在回答的过程中也可能存在不愿意透露信息、针对社会敏感性话题不愿表达真实想法等问题; 采访或实验设计中的具体环节, 如不同采访者在不同访谈场次中的表达、能力、个人特征的不同、实验中刺激的不同等都会对数据获取产生影响, 致使所测量数据与理想中的变量值不完全相符, 影响参数估计的一致性和因果关系的推断。
测量误差包括因变量的测量误差和解释变量的测量误差, 但因变量的测量误差一般不会影响参数估计的一致性。因为通常的假设是因变量的测量误差与解释变量是独立的, 这也就意味着回归方程的扰动项与解释变量是不相关的。所以因变量的测量误差通常不会导致内生性问题。假设在下面这个简单 OLS 模型中:
根据 OLS 的假设, E( εi) = E( μi) = 0 , Cov( xi, εi) = 0 , 如果 y* i 的测量误差与解释变量和方程扰动项误差无关, 那么 Cov( xi, μi) = 0 , Cov( εi, μi) = 0 。显然, 此时回归方程 ( 13) 和 ( 14) 都会给出一个 β 的一致无偏估计。但是由回归方程 ( 12) :
所以因变量的测量误差虽然不影响参数估计的一致性, 但会导致参数估计值的方差变大, 而当解释变量存在测量误差时就无法得到参数的一致性估计。一般而言,定量分析中都更关注回归方程能否给出一个一致性的估计, 所以测量误差通常指的就是回归模型使用到的解释变量的数值和解释变量的真实值之间的误差。就产生的过程来看, 该误差往往与自变量本身相关, 且在计算中往往会被视为随机误差而被归入残差项中, 并导致所观测的自变量与残差项相关, 引发内生性问题。假设在下面这个简单 OLS 模型中,
也就是说, 解释变量存在测量误差时会引发内生性问题, 而且此时简单的 OLS回归模型无法提供一个一致性的估计。回到上文所提及的 “社会敏感性话题”调查的问题, 如探究对某类群体的偏见 ( 地域偏见、性别偏见、种族偏见等) 的影响时,在受访者评估自己的偏见态度水平时, 可能会存在为了保持 “政治正确”而隐瞒自己真实态度的情况, 观察数据就会较真实情况而言更积极, 该态度差距即为偏差 vi ,且其与观察数据 “态度”xi 相关联, 所以当此差距在回归运算中被计入到残差项时,“态度”xi 便有一部分会源自内生。
总体而言, 测量偏差可分为两种: 一种聚焦于观察变量与非观察变量①, 观察变量的测量偏差问题指的是受访者的反馈偏离研究者所关注的测量值, 这种测量偏差可能源自数据获取过程中的每一个元素, 如问卷设计、受访者、调查者等, 以及数据的收集模式设计与方法等; 非观察变量的偏差指的是由于对样本的某些部分缺乏测量而产生的误差, “覆盖率、无响应 ( 单位和项目均无响应) 和抽样”是其产生的主要原因。
另一种指的是 “均值平方偏差”, 即方差与偏差的平方的和②, 其中方差是与调查的特定实施相关联的变量偏差的度量, 如问题的具体提问语句或采访者的具体人选, 该变量的可重复性是准确测量的关键要素, 若在不同访谈场次中提问语句有变,那么调查的提问环节会存在额外的方差。偏差则是指在一组确定的必要调查条件下,影响调查全过程的偏差, 是一种恒定的偏差 ( Hansen, M. et al. ) ③。如在自变量 “教育”与因变量 “收入”间的多元回归方程中, “能力”常被视为一个重要的自变量列入其中, 但 “能力”概念很难通过两三项数据完整地量化出来, 可能会被总体地低估或高估, 这种未能完整表达的偏差便是一种恒定的偏差, 贯穿调查的全部实施过程。
在传播学领域中, 测量偏差问题也很常见: 在政治传播领域中, 如何完美地衡量线上政治参与、线下政治参与以及互联网使用深度等是一个巨大的难题。尽管有众多学者提出了相应的测量项目, 如通过测量 “参加政治会议、集会或演讲”、“为政治候选人或政党工作”、 “为政治活动捐款”项目量表来具化 “线下政治参与程度”( Gil de Z iga, H. et al. ) ④; 以八个二分项 “衡量受访者在过去两年中是否参加过与政治有关的会议; 是否给报纸编辑写信或参加公共事务广播谈话节目; 是否为某一候选人或议题散发请愿书; 是否为某一当选官员投票; 是否为某一政治活动工作; 是否与某一公职人员联系; 是否召集其他人为某一政治组织筹集资金; 是否为某一政治组织或候选人捐款”来衡量受访者的政治参与情况 ( Hardy, B. W. etal. ) ①。可见, 在将某些概念转化为数据的操作化进程中还存在着很多模糊的问题:一, 程度量表与二分量表所包括项目是否能真实无差别地反应变量概念? 二, 不同国家、文化、地域的学者在相互探讨、引用、借鉴彼此的量化方法时, 这些方法是否真的能跨越政治文化的差距而起到效用? 答案是不能或者是很难。这便是 “均值平方偏差”所指的问题, 因为概念难以被完全地量化而导致的测量偏差。
同时, 传播学中也不缺少观察变量类的测量偏差, 如大多数研究者采用的调查问卷这一数据获取方法, 就问卷调查本身而言, 问卷可以保证每一位受访者每一次所遇到的问题是完全相同的, 不会产生额外的方差, 但同时, 自填的问卷难以保证受访者的认真程度, 如有以大陆多所高校学生为受访者的调查研究②, 其问卷的成功回收率仅有 32% , 那么该 32% 成功回收的问卷的有效性与真实性也可能会受到质疑; 就受访者而言, 其可能会因为担心隐私泄露而勾选非真实的选项, 或是基于身份原因选择更 “正确”的答案。如在对留美的中国留学生的本国文化认同的问卷中③, 在描述性统计部分研究者得到了一个积极的文化认同结果, 但该类问题的设置本身就很难得到一个无偏的答案。
但值得了解的是, 自填问卷的认真程度难以得到保障这一问题并不会通过转变为指导性填答而得到解决, 因为即便指导者可以使问卷的语义、目的更清晰地呈现给受访者, 督促受访者更认真地对待此次填写, 但不同的指导者、同一指导者的不同状态与穿着也都可能会影响到受访者的填答, 所以观察变量的测量偏差也很难得到解决。
五、讨论
随机实验通常被认为是识别变量之间是否存在因果关系的最值得信赖的方法。但是在社会科学, 尤其是在新闻传播学中, 进行各类实验和准实验方法往往需要投入大量的资金、要受道德伦理的约束, 经常还需要一些运气成分甚至有时候根本不可能进行④。所以在现实的科研活动中, 新闻传播学领域大量有价值的研究不得不依赖非实验数据展开。使用观测数据来进行因果关系推断, 比如识别媒体使用和个体行为或态度之间的因果关系时, 一个难以避免的问题就是数据的内生性问题, 也就是解释变量和残差项相关。在 “观测数据———回归分析”的研究模式下, 内生性对因果关系造成的影响通常无法被有效剔除。这样一来, 回归模型所得出的参数估计就与总体不一致。这些观测数据虽然可以帮助研究者们检验变量间的相关关系, 但是也经常需要更精巧的研究设计来更进一步地识别变量间的因果联系。
本文通过对近年来新闻传播学领域使用的定量研究方法教材以及采用量化方法的科学研究论文进行回顾, 发现处理 “内生性问题”可能会成为未来传播学定量研究的重要内容之一。文章采用代表性较强的 “在调查数据 ( survey data) 的基础上使用多种回归方法并做出因果推断”的研究为 “定量研究”的主要讨论对象、以普通最小二乘法 ( ordinary least squares) 为主要分析模型, 以新闻传播学中的经典变量关系为案例, 对什么是内生性问题、相关关系与因果关系的区别、内生性问题对因果推断产生的影响, 以及形成内生性问题的原因进行了深入介绍和探讨。值得注意的是, 目前在新闻传播学领域的不少研究都是通过增减模型中的解释变量并观察回归方程给出的 R2 的变化来验证解释变量对因变量的影响。此类方法只能检验解释变量和因变量之间的相关性, R2 的变化本身并不能说明变量之间有或没有因果联系。
必须指出的是, 尽管内生性问题是对新闻传播学研究中因果关系识别的严重威胁, 但这并不意味着以 “观测数据———回归分析”为研究模式的相关关系研究是没有意义的。相反, 许多关于变量之间的相关性定量分析是积极的, 也是十分必要的。在因果分析条件难以满足的情况下, 很多变量间的相关关系研究可以成为日后因果分析的基础, 可以凭借相关性的可预测性而成为政策制定的有力论据, 还可以对具体的学科实践提供依据。例如 “观看暴力影视”和 “校园霸凌行为”这两个变量间的关系。要进行因果关系推断就需要剔除内生性问题的影响、保持变量外一切要素不变等条件。这对于社会性较强, 且难以进行实验的 “观看暴力影视”和 “校园霸凌行为”等变量而言难度太高了, 所以很难得出规范合理的因果关系。但这并不表明两者间可能的相关关系是无意义的, 在 “观看暴力影视”与 “校园霸凌行为”正相关的情况下, 相关机构就可以以此为依据, 对暴力影视进行分级, 规定不同年龄段儿童可观看的暴力级别, 以减少校园暴力。
因此, 研究者们对因果关系的追寻并不抹杀相关关系的探索与实践意义。不过,新闻传播学学科的发展也确实需要进一步探讨诸如媒体使用与个体的态度和行为之间的因果联系。基于此, 本文建议改进研究方法课程的内容, 将处理传播学研究中遇到的内生性问题视作未来学科教学和科研的一个发展方向, 并在此给出三点具体建议:
一、加强各类实验方法, 包括调查实验 ( survey experiment) , 田野实验 ( fieldexperiment) 包括自然实验 ( natural experiment) ) 和实验室实验 ( lab experiment) 的教学和科研应用。提升数据质量, 尽可能获取更 “完美的”数据是检验理论假说最有效的途径之一。各种实验和准实验方法可以从数据源头入手, 通过完美的实验设计等方法来解决内生性问题背后的本质难题———在获得样本数据时无法保持其他条件完全不变, 无法独立考量处置变量的影响等等。当然, 实验法也具有一些需要额外考量的因素, 如实验所需要的物质支持; 实验所需要遵守的道德伦理标准, 有一些挑战伦理的实验只能停留于想象层面; 实验所需要的运气, 如自然实验的发生时间、地点等, 具有一定的巧合与偶然性。
二、在无法应用各类实验方法的情况下, 基于 “观测数据———回归推断”的模式, 可以考虑新的研究设计方案, 对非实验数据进行更有效的识别。比如使用断点回归分析 ( regression discontinuity) 、双重差分模型 ( difference in difference) 和工具变量 ( instrumental variable) 等方法来尽可能的剔除内生性问题的影响, 即运用调查数据模拟真实实验来获得接近真实情况的因果关系①。
三、强化新闻传播学的学科理论构建。在有效的研究设计基础上的定量研究,无疑会帮助新闻传播学检验和构建学科理论。但是理论逻辑本身也是指导实证研究的重要依据。强大的理论支撑和有效的研究设计, 会使回归变得更有意义。正如肯德尔 ( Kendall) 和斯图亚特 ( Stuart) 所说: “一个统计关系式, 不管多强也不管多么有启发性, 永远不能确立因果方面的联系: 对因果关系的理念, 必须来自统计学以外, 最终来自这种或那种理论。”②
本文为我们研究方法系列论文的第一篇, 重点讨论了新闻传播学定量研究中的内生性问题。在后续论文中, 我们将分别从 “实验和准实验”、“基于观测数据的研究设计”、“实证研究与理论构建”和 “‘好的’控制变量”等方面为主题来进一步探讨如何解决内生性问题以及新闻传播学中研究方法方面的其他重要问题。
作者: 武汉大学新闻与传播学院副研究员
武汉大学新闻与传播学院硕士生
武汉大学新闻与传播学院硕士生