一、研究缘起:从算法引发的争议谈起
算法的社会权力日益强大,而传统把关人所遵循的职业规范和新闻伦理并不约束算法系统,后者运作的“黑箱化”给问责设置了重重阻碍,继而引发了诸多问题。在这样的背景下,我们迫切需要了解算法究竟是如何把关的,以及遵循何种价值观念和标准。
微博是中国的超级平台之一。鉴于此,笔者试图从批判算法研究的视角出发,以微博为研究对象,探讨中国语境下超级平台的算法把关标准。中国语境下的相关研究有助于我们更好地理解算法的内嵌性,即算法在不同语境下的社会建构。
二、文献回顾与核心概念
(一)批判算法研究
随着算法渗透信息生产、分发与消费日益深入,相关的社会科学研究也开始兴起,其中,批判算法研究是较有代表性的研究取向。新英格兰微软研究院首席研究员Tarleton Gillespie是该研究取向的倡导者和推动者,他和学者尼克·西弗(Nick Seaver)总结了一份详尽的阅读清单,概括了批判算法研究的五个维度(Gillespie & Seaver,2016):
第一,研究算法的特定影响与选择逻辑。这部分还可以细分为三个层次:首先,算法具有内嵌的价值观与偏见,可能导致个体化、社会分类与歧视;其次,关注经由算法运作的理性化、自动化和量化带来的对于人类社会评价标准、复杂程度以及语境的化约与抹除;最后,关注与算法相关的政策回应与可信度问责。
第二,算法帮助维持或强化某种特定的意识形态观念,例如资本主义、监视、主体与客体(Cheney-Lippold,2017)。
第三,算法是复杂的技术组件,需要考虑其内嵌性(situatedness),即算法运作过程中与“规则、人、过程、关系”等的相互作用(Neyland & Möllers,2017)。此类研究多从行动者网络理论的视角出发。
第四,算法本质上由人来设计,也由人来使用。这一维度主要关注人们如何以特定的方式设计与维持算法,如何与算法共同生存,用户对算法的认知调查,以及算法如何形塑人们对公共议题的感知等议题。
第五,探讨研究算法系统的方法和路径。学者和媒体从业人员采用逆向工程、算法审计、众包等多种方法来研究算法和自动化决策系统。
本文最为关注的是第一个维度的相关研究,尤其是算法内嵌的价值观、可能存在的偏见,以及运作的非中立性(non-neutrality)。
(二)算法把关
记者、编辑控制信息的霸权地位受到了平台媒体、用户、算法等的多重挑战。本文重点关注算法所发挥的把关角色。鉴于把关人理论所具有的丰富意涵,本文统一采用“算法把关”的概念来指代算法所进行的“所有形式的信息控制”,包括选择、聚合、分类、排序、过滤、组织、呈现、推荐。
随之而来的问题是,算法是如何把关的?和编辑把关相比,它具有什么特征?早在20世纪,美国逻辑学家和计算机科学家罗伯特·科瓦尔斯基(Robert Kowalski)就提出一个关于算法的经典定义:“算法=逻辑+控制”(Algorithm=logic + control)。其中,逻辑部分指定使用哪些知识(数据)来解决问题,而控制部分则决定使用什么策略来解决问题。逻辑部分决定算法的意义,而控制部分仅仅影响算法的效率(Kowalski,1979)。因此,算法既不完全是物质的,也不完全是人类的——它们是混杂的,由人类意图性(human intentionality)和物质顽固性(material obduracy)共同组成(Anderson,2013)。这种混杂性使得算法把关具有区别于编辑把关的如下特征:
(1)数据化(datafication)。数据化是指网络化平台将现实世界的多个方面(如用户的线上行为、社交关系、地理位置)转化为数据的能力(Dijck & Poell,2013),它赋予了平台媒体实时分析、预测和个性化推荐的潜力。
(2)程序化(proceduralization)。算法遵循“如果/那么”逻辑(“if/then”logic),按照预先设定好的指令程序化地运作。所有的人类构念(human constructs)事先都被转化为了具有可操作性的变量、步骤和指令(DeVito,2017)。
(3)自动化(automation)。在完成初期的设计和编程后,不经人为干预,算法即可自动完成信息的把关。
上述特征为算法把关披上了“机械中立性”(mechanical neutrality)(Gillespie,2014)或“计算客观性”(calculative objectivity)(Beer,2017)的光环,并对人工把关模式提出了根本挑战。“人的主观性本质上是受到怀疑和需要代替的,而算法本质上是客观和需要执行的”(Carlson,2018)成为了一种盛行的观点。
批判算法研究驳斥了上述观点,算法运作的非中立性已经成为了一种共识(Gillespie & Seaver,2016)。个人因素(如程序员的偏好和价值观念)、组织因素(如企业的方针政策、企业文化)、外部因素(如广告主的诉求、法律规范)等都会影响算法的设计和编程,即科瓦尔斯基所说的逻辑部分。此外,研究发现,算法把关也会带来虚假新闻传播(Carlson,2018)、有价值的新闻被压制(Tufekci,2015)、歧视和偏见(Baker & Potts,2013)、过滤气泡(Pariser,2011)等负面影响。
综上所述,算法把关拥有其独特的逻辑和合法性基础,并对编辑把关提出了根本挑战。二者的共同点在于,都不可避免地受到多个层次因素的影响。
(三)算法把关标准
随着算法成为新兴的把关主体,算法用来选择和衡量新闻价值客体的标准是什么?包含哪些要素?学者对内嵌于不同平台媒体中的算法系统及其把关标准进行了考察。这些标准常常是由程序员、算法工程师等事先定义好的、可编程的,且处于流动之中(Wallace,2018)。
可见,针对脸书、谷歌、推特等西方超级平台的算法把关标准,学界已经有了较为丰富的研究成果,而非西方语境下的系统研究仍较为缺乏。本文尝试从批判算法研究的视角切入,以微博“热搜”为研究对象,探讨中国语境下超级平台的算法把关标准。在智能算法得以广泛应用和推广的大势所趋之下,探究该问题有助于我们更好地理解和把握当下新闻传播领域正在发生的权力转移和深刻变革。
三、研究设计
(一)研究对象
本文选取微博“热搜”作为研究对象,原因有二:其一,微博是中国最重要的互联网公共表达平台之一,而“热搜”常常被认为是公共讨论的“晴雨表”和“风向标”,发挥着重要的把关和议程设置作用。其二,“热搜”功能是算法分发模式在社会化媒体的典型应用。
(二)研究方法
Kitchin(2017)在《批判性地思考和研究算法》一文中,提出了研究算法的六种方法:研究伪代码和源代码,反射地生成代码,逆向工程,访谈或民族志,对公开材料的文本分析,检验算法在现实世界的运作。鉴于笔者不具有编程技能,且算法价值观是平台媒体的核心商业机密,本研究主要采用第五和第六种研究方法。
1.对微博公开材料的文本分析
笔者搜集了微博发布的年度报告、新闻稿、专利、核心人物(如微博CEO、微博副总裁等管理人员)访谈,以及“微博热搜榜”“微博搜索”“微博管理员”“微博客服”“微博小秘书”等官方账号发布的公开声明,从中找出与“热搜”“规则”等相关的内容。基于对上述材料的文本分析,笔者梳理了“热搜”上榜规则所经历的调整,从而把握算法价值的演变。
2. 对“最热搜”上榜词的文本分析
分析公开材料仅能够揭示微博如何对外宣称“热搜”的算法价值,鉴于此,笔者还试图检验在实际的运作中,哪些内容优先通过了“门卡”,哪些内容被排除在外。这在一定程度上可以逆向推导“热搜”的把关标准,然而不可避免地难以勾勒出全貌。
鉴于“最热搜”是每日榜首热点的集合,在榜时间更长,讨论范围更广,笔者手动记录了2018年2月3日至9月18日所有上榜“最热搜”的搜索词及其人气值、在榜时间,共得到2404条。由于人气值和在榜时间在当日处于不断的变化之中,笔者采用次日记录的方式,此时数值在多数情况下已趋于稳定。9月19日,微博改版,“最热搜”版块下线,故而资料搜集中断。此外,笔者以“登不上热搜”“无法登上热搜”“难以等上热搜”等为关键词,检索用户于记录期间发布的微博,从中筛选出用户认为理应上榜的新闻事件(见表1)。

四、研究发现:微博“热搜”的算法价值四要素
基于对“最热搜”上榜词的分析,笔者提炼出了微博“热搜”算法价值的四个要素,分别是:时新性、流行性、参与性和导向正确。下文将分别进行讨论。
(一)时新性
时新性是指“热搜”上榜词在时间上是新近乃至正在发生的,在内容上是新奇的。
2017年3月,“热搜”由每10分钟更新一次,提升至每1分钟更新一次。根据改版时的声明,“新版热搜榜不同于按照固定时间段搜索热度累积来衡量的榜单,将更加凸显此时此刻正在发生的热点事件”(新浪,2017)。对实时更新的推崇和强调,给人以一种人工无力完成,因而运作过程是自动化的、免受人工干预的印象(Duguay,2018)。
此外,通过对2404条“最热搜”上榜词的分析,笔者发现常规化的词汇难以登上“热搜”,上榜词常常具有新奇性、异常性。
在笔者为期228天的观察和记录过程中,除了极少数搜索词能够重复登上“最热搜”,绝大多数搜索词仅仅上榜一次。这与大众媒体的把关标准相一致,那些曾经出现过的新闻故事难以再次通过筛选过程(White,1950)。对内容新奇性的强调还使得常规性、持久性的议题被边缘化。
(二)流行性
流行性是指内容所具有的易于为多数人所喜爱并突然间迸发的性质。微博在多份官方声明中也强调,排行榜是“依据用户的真实搜索量”(微博热搜榜,2016),“基于实时搜索数据计算而来”(Weibo,2018)。
上述测量方式暗含了这样的逻辑:多数人实时搜索了什么,什么就是热门。使用算法来挖掘用户的数字痕迹通过三种“抹除”(exclusion)造成了“多数人的暴政”(the tyranny of the majority):数据采集过程中对细节和社会情境的抹除,基于“大数法则”进行预测造成了对离群值和差异的抹除;对既有网络的强化、偏袒造成了对新声音、弱小声音的抹除(Harper,2017)。在这种逻辑之下,流行的人(如明星、网络红人)、流行的事物(如世界杯、热门电视剧)大行其道,而少数群体的声音(如同性恋、残疾人、农民)被边缘化。
参照“微博热搜榜”(2016)使用的分类标准,笔者将2404条上榜词分为以下四种类型:娱乐类新闻资讯、非娱乐类新闻资讯、新生事物和影视综艺。如表2所示。名人拥有远高于普通民众的可见度和曝光量,且很多议题(如6月1日的“HIV感染者与明星首次出镜”)只有在涉及到名人时才会突然间迸发。
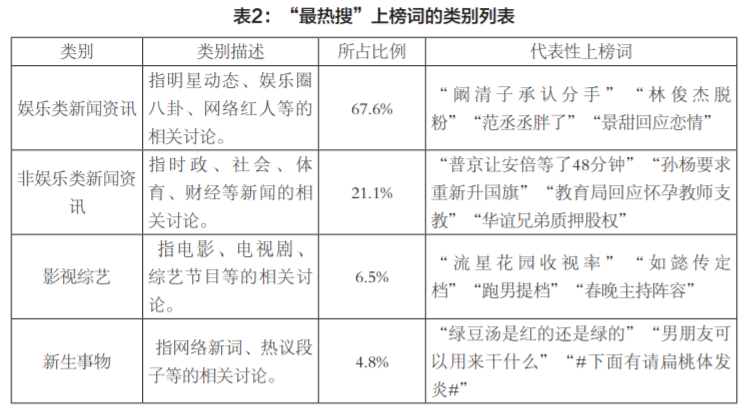
图1是基于“热搜”人气值制作的直方图。可以看到,大多数情况下,人气值达到100万以上才能上榜“最热搜”,多数上榜词的人气值集中在200万至400万之间,有的能达到一千万以上。
(三)互动性
互动性是指内容所具有的易于促进用户参与和社交行为(如点赞、评论、转发、关注)的性质。如前所述,自2018年3月15日起,“热搜榜”排序规则从单一考量“搜索热度”转变为“(搜索热度+传播热度)*话题因子*互动因子”的多重考量。其中, “搜索热度”以搜索量为基础,反映用户对热点的关注和探索的程度;“传播热度”以热点相关博文阅读量为基础,反映热点触达人群的规模;“话题因子”以话题讨论量为基础,反映用户热议和参与的热情;而“互动因子”以结果页转评赞互动率为基础,反映用户消费内容的意愿(微博MCN,2018)。笔者观察记录期间,共有148条包含双井号的话题上榜。

尽管从表面上看,“热搜”仍然是原来的排行榜,然而其对“热门”的界定及测量方式发生了根本改变,互动性开始成为重要的价值要素。
此外,微博设置“好友搜”版块,展现多个好友共同搜索过的内容;开发“你可能认识的人”功能,促使用户扩大关注范围,均是为了提高用户和用户之间、用户和内容之间的互动。学者称之为“编程的社交性”(programmed sociality),即算法和软件深度介入到了人际关系网络的创建、维系、形塑和组织过程之中(Bucher,2013)。
值得注意的是,并非所有用户的搜索、互动和参与都会被同等地纳入考量。“微博管理员”在《关于“紫光阁地沟油”从未进入微博热搜榜的说明》中指出,“热搜”计算主要依据的是“可信用户的搜索行为”,为了防止刷榜,还会考虑用户群分布、终端系统分布、搜索操作特征等维度。微博的出发点是保证榜单的真实性和可信度,然而在具体运作过程中,却会出现“算法误判”,造成意料之外的负面影响。
(四)导向正确
作为中国最有影响力的社会化媒体和新闻获取的重要渠道,微博也被纳入了日常媒介规制。需要指出的是,导向正确并非一开始就由平台媒体自觉纳入算法设计价值,而是经过了一系列监管措施之后,才开始受到平台媒体的重视。
整改后的“热搜”上线“新时代”频道,从而更好地宣传十九大精神,弘扬社会主义核心价值观,报道中国新时代的社会风貌(观察者网,2018)。笔者观察记录期间,有46条正能量搜索词登上榜首,它们弘扬了家庭和谐 、爱岗敬业、友善互助、自强不息等中国传统价值观念。
与此同时,对导向正确的强调也可能造成大量具有公共性的搜索词(如表1列出的社会新闻)无法登上“热搜”或是被撤出榜单,发展成为一种变相的信息审查。
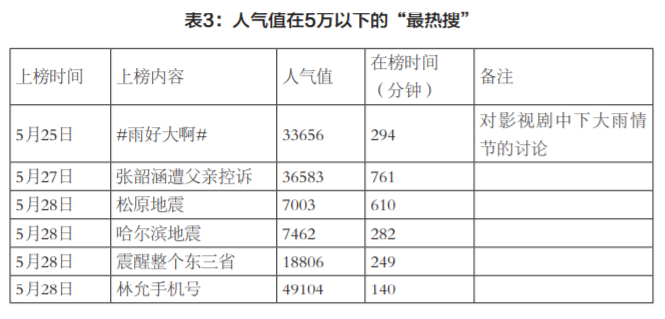
除了上述四个算法价值要素之外,其他价值要素(如重要性)也在一定程度上被微博纳入了考量,然而并不占据主要地位。笔者注意到,人气值在5万以下的搜索词(见表3)也曾登上榜首,且集中出现在5月25日至28日期间;一些搜索词的热度还在1万以下。据笔者推测,微博在此期间试图对算法价值进行更改和调试,将具有重要性、突发性(如自然灾害)的新闻放置在“热搜”的显著位置,给予更长的曝光时间。这呼应了微博此前的声明,整改后的“热搜”会在选择和排序上放弃纯粹的算法模式,引入编辑人工干预模式。
然而,这一改革和尝试并未持久推行。“热搜”仍然主要遵循“热度优先”原则,其原因可能在于“人机协作”会破坏“热搜”试图建立和维持的自动化运作、因而免受人工干预的形象。由此可见,微博注重对用户数字痕迹的聚合和呈现,而弱化了编辑所秉持的核实原则。
五、讨论与结论
(一)研究的理论价值和应用价值
本文采用批判算法研究的视角,对微博“热搜”的算法把关标准进行了考察。研究发现,微博“热搜”的算法价值要素主要包括时新性、流行性、互动性和导向正确。以上要素反映了微博关于“什么应当算作‘热门’”的假设,其价值观被推向了“上游”阶段:无论是数据来源的界定(如保留“可信用户”的搜索,排除“刷榜”数据)还是指标的设定(如“热搜热度”“传播热度”“互动因子”和“话题因子”的定义及测量方式、各个价值要素的权重),都在算法的设计和编程阶段被转化为了可操作的指令。
算法的创建并非出于中立目的,而是为了创造价值和利润,以某种方式助推行为或构造偏好,或对人进行识别、排序和分类(Kitchin,2017)。尽管中西方平台媒体都以盈利为主要目标,然而本研究揭示了中国语境下平台媒体算法价值不同于西方的独特一面。尤其是在宣传新闻主义观念的指导下,导向正确要素被纳入中国平台媒体的算法设计价值。除了微博强调“更高的价值标准和更大的责任担当”(微博管理员,2018)之外,快手CEO宿华(2018)表示要“用正确的价值观指导算法”,今日头条CEO张一鸣(2018)也承诺要“将正确的价值观融入技术和产品”,这与其早期的定位——“没有采编人员,不生产内容,没有立场和价值观,运转核心是一套由代码搭建而成的算法”——形成了强烈反差。
Anderson(2013)提出了算法新闻学研究的六种社会学路径:政治和公共政策视角、经济视角、制度和场域视角、组织动力学视角、文化-历史视角以及技术与新闻视角。其中,第一种路径关注新闻业所处的政治情境,尤其是“公共政策决定如何促进或限制算法新闻的发展”。未来研究可以进一步探讨中国语境下政治力量对算法新闻的规训。
此外,本研究揭示了“人机联姻”在具体执行过程中的复杂性。尽管微博表示将放弃纯粹的算法模式,引入编辑人工干预模式,然而在具体实施过程中仍然不遗余力地建构和完善以“机械中立性”和“计算客观性”为核心的合法性话语。微博使用了一系列策略来使“热搜”生成过程看起来浑然天成且不可避免,包括人气值的实时更新、搜索框提示“大家正在搜”、以及“呈现”“反映”等修辞的使用。
根据批判算法研究的已有文献,算法把关并不是对公共讨论镜子式的“呈现”和“反映”,它也在“引导”和“形塑”。“‘原始数据’是一种修辞”(“rawdata” is an oxymoron)(Gitelman, 2013),平台媒体使用的采集机制决定了它最终能够获取什么样的数据。正如威廉斯所指出的,“群众是不存在的,所存在的只是把人民视作群众的方式”(Williams,1958:300)。相应地,“大家正在搜”中的“大家”是不存在的,所存在的只是“热搜”算法按照一定的标准对“大家”的建构。Gillespie(2014)称之为“计算的公众”(calculated publics),即人们只能通过算法生成结果(如“热搜”人气值)来感知“大家”的存在,然而其具体构成是模糊的、不透明的,且可能存在偏见。
值得注意的是,微博“热搜”的合法性在一定程度上得到了大众媒体的接纳。社会化媒体逻辑和大众媒体逻辑的日益交织,是值得继续探讨的问题。除了理论价值之外,研究微博“热搜”的算法把关标准还有重要的应用价值。腾讯网络媒体总编辑陈菊红曾指出,作为最大的信息原生地和中转地,社交平台调一下“指针”,就会影响一批内容生产者的流量(腾讯传媒研究院,2016:Ⅰ-IV)。她所说的“指针”在很大程度上是指算法的设计价值。随着“热搜”将垂直度纳入考量,时尚和美妆两个领域的流量较前一年增加了3倍(曹增辉,2019)。
在超级平台日益主导新闻分发的当下,“内容为王”“酒香不怕巷子深”的思维模式亟需转变。搜索引擎优化(search engine optimization,SEO)、社会化媒体优化(social media optimization,SMO)、自动化推荐系统等都对内容的组织和呈现方式提出了新的要求。新闻从业者需要了解平台媒体的推荐规则和算法逻辑,从而更好地应对蓬勃而至的智媒化浪潮。
(二)研究的局限性和不足
需要指出的是,算法和用户之间并不是单向影响的关系,而是紧密地交织和勾连(entanglement)。Dijck和Poell (2013)在《理解社会化媒体逻辑》一文中指出,算法的权力主要体现在编程性(programmability)。本研究的一大不足,是未充分考察用户使用行为和实践对平台的形塑。
为了弥补用户研究的不足,未来可以借鉴Chakraborty等(2017)对算法“输入”的研究。此外,算法的“黑箱”特性和流动性是本研究面临的两大挑战。一方面,算法被视作核心商业机密而讳莫如深,是难以探查的“黑箱”(帕斯奎尔,2015/2016:6)。鉴于此,单纯依赖文本分析和逆向推导得出的结论具有一定的局限性。未来研究可进一步通过深入平台媒体内部,与算法架构师、程序员、编辑等开展深度访谈,或采用民族志等研究方法来获取一手材料。另一方面,平台媒体所采用的算法系统并不是静态的、一成不变的,而是在不断地演进、优化和迭代。因此,本研究的结论需要进行阶段性地重访和更新。